
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 유데미큐레이션
- 데이터도서
- AARRR
- 토스
- 딥러닝
- 추천시스템
- sql정리
- 유데미부트캠프
- NLP
- SQL
- 그래프
- 알고리즘
- 부트캠프후기
- SLASH22
- 스타터스부트캠프
- 취업부트캠프
- AWS builders
- 취업부트캠프 5기
- pytorch
- MatchSum
- 그로스해킹
- 특성중요도
- 서비스기획부트캠프
- BERT
- 사이드프로젝트
- 서비스기획
- 임베딩
- 스타터스
- 유데미코리아
- NLU
- Today
- Total
다시 이음
선형대수 -3 ( 고유벡터, PCA ) 본문
고차원 데이터 처리
선형변환( Vector transformation )
- 임의의 두 벡터를 더하거나 혹은 스칼라 값을 곱하는 것을 의미
- 행렬은 벡터를 변환시켜 다른 벡터를 출력
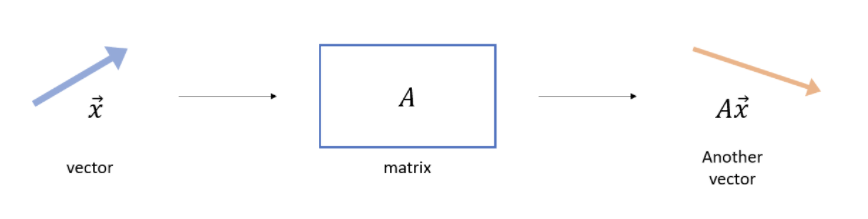
벡터(x)에 행렬을 더하거나 곱하여 출력된 새로운 벡터(Ax)는 크기와 방향이 변화한다.
그중 크기는 변화하였지만 방향이 변화하지 않는 벡터를 우리는 고유벡터(Eigenvector)라고 한다.
임의의 n×n 행렬 에 대하여, 0이 아닌 솔루션 벡터(x)가 존재한다면 숫자 는 행렬 의 고유값(Eigenvalue)라고 할 수 있다.
여기서 솔루션 벡터를 다시 고유벡터라고 보면 된다.

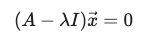
위의 특성 활용에서 두가지를 확인할 수 있는데 벡터(x)의 값이 0이거나 앞에 스칼라부분이 0이어야 한다
위의 내용을 아는 것이 주 목표였고 여기서 고유벡터와 고유값을 구하는 방법은 심화이다.
궁금하다면 https://angeloyeo.github.io/2019/07/17/eigen_vector.html 참고!
고차원의 문제 (The Curse of Dimensionality)
데이터에 지표(feature)수가 많으면 생기는 여러 문제들
Dimension Reduction
위의 고차원의 문제를 해결하기위해 우리는 차원을 축소하는 방법을 거쳐야한다.
이중 유용(중요)하게 볼 수 있는 feature을 선별할 때에 분산도가 높을 수록 변별력이 높아 중요하다고 파악한다.
방법
Feacture Selection:
- 기존의 있던 feature 혹은 그것을 토대로 조합한 feature을 사용
- 해석이 어렵다.
- ex) PCA, Auto - encoder
Feature Extraction:
- feature중 덜 중요한 것을 제거하여 사용하는 것.
- 해석이 쉬우나 feature간 연관성을 고려해야한다.
- ex) LASSO, Genetic algorithm
Principal Component Analysis (PCA) - 주성분 분석
PCA는 데이터의 분산(variance)을 최대한 보존하면서 서로 직교하는 새 기저(축)를 찾아, 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간으로 변환하는 기법입니다.
참고 - https://ratsgo.github.io/machine%20learning/2017/04/24/PCA/
요약해서 말하자면 분산도가 큰 feature 2개를 선정하여 그에 따른 산포도를 만들고, 산포도에 원점을 지나는 고유벡터를 하나 지정 그 선위에 산포도의 점들을 투영시켜 원점과의 거리를 측정한다.
각각의 거리를 제곱하여 총합한 값을 SS(distance)라고 한다. 이 값이 가장 최대가 될 때 즉 피타고라스의 정리에 따라 밑변의 길이가 가장 길어짐에 따라 높이(선과 점과의 거리)가 가장 작아질 때를 구하여 PC1이라고 지정한다.
그와 같이 PC1에 직교하는 선을 PC2로 지정, 그 후 두 선을 선형변환을 하여 x축, y축으로 지정하여 나타낸 값을 PCA라고 한다.
PCA 구하기
1) 계산식을 통해 구하기
#각 열에 대해서 평균을 빼고, 표준편차로 나누어서 Normalize를 함.
standardized_data = ( X - np.mean(X, axis = 0) ) / np.std(X, ddof = 1, axis = 0)
print("\n Standardized Data: \n", standardized_data)
#Z의 분산-공분산 매트릭스를 계산함
covariance_matrix = np.cov(standardized_data.T)
print("\n Covariance Matrix: \n", covariance_matrix)
#분산-공분산 매트릭스의 고유벡터와 고유값을 계산함
values, vectors = np.linalg.eig(covariance_matrix)
print("\n Eigenvalues: \n", values)
print("\n Eigenvectors: \n", vectors)
#데이터를 고유 벡터에 projection 시킴. (matmul)
Z = np.matmul(standardized_data, vectors)
print("\n Projected Data: \n", Z)
2)라이브러리를 통해 구하기
from sklearn.preprocessing import StandardScaler, Normalizer
from sklearn.decomposition import PCA
print("Data: \n", X)
scaler = StandardScaler() # 데이터 표준화
Z = scaler.fit_transform(X) # 표준화 데이터 저장
print("\n Standardized Data: \n", Z)
pca = PCA(2)#'사용할 지표 개수'
pca.fit(Z)
print("\n Eigenvectors: \n", pca.components_) # 고유벡터 구하기
print("\n Eigenvalues: \n",pca.explained_variance_) # 고유값 구하기
pca.explained_variance_ratio_ # pc로 설명되는 variance의 ratio 구하기
B = pca.transform(X)
print("\n Projected Data: \n", B)Scree Plot
- PCA(주성분 분석)을 사용할 때 PC를 몇가지 사용했을 때 전체 데이터를 대표할 수 있다고 생각할 수 있을까?
- 이러한 궁금증을 풀기 위한 Plot으로 내가 사용한 PC가 얼마나 설명력이 있나를 알 수 있다.
- 이 그래프의 기울기가 급격하게 변화할 때 혹은 이후 변화되는 수치가 미세할 때 그 전단계의 PC개수까지를 사용하여 PCA를 실행하면 최적의 분석을 할 수있다.

위의 그래프를 보았을 때 PC3이후로는 변화가 미세하여 PC2까지 사용해도 충분히 데이터에 대한 설명력을 갖춘다고 판단할 수 있다.
pca.explained_variance_ratio_를 시각화 한 것과 같다.
One Hot Encoding
- 단순 수치형 형태의 데이터가 아닌 문자형인 범주형 데이터를 분석하고 싶을 때 컴퓨터가 인식할 수 있는 데이터로 변환을 해줘야 한다.
- 이 방식을 사용하면 범주형 데이터를 0,1을 가진 벡터로 변환이 가능하다.
- sklearn 라이브러리의 OneHotEncoder 사용
from sklearn.preprocessing import OneHotEncorder
onehot_encoder = OneHotEncoder(sparse=False) #sparse True면 행렬 반환, False는 array 반환
onehot_encoded = onehot_encoder.fit_transform()
추가 참고 자료
https://rpubs.com/Evan_Jung/pca
https://brunch.co.kr/@sokoban/8
'AI 일별 공부 정리' 카테고리의 다른 글
| 데이터를 적절하게 시각화 해보자 -1 ( feat. python) - 분포, 상관관계 (0) | 2021.08.05 |
|---|---|
| 선형 대수 - 4 ( Supervised Learning / Unsupervised Learning ) (0) | 2021.07.27 |
| 선형대수 - 2 (공분산과 상관계수) (0) | 2021.07.23 |
| 선형대수 -1 (벡터, 매트릭스) (0) | 2021.07.22 |
| 데이터 통계 - 4 (베이즈 정리) (0) | 2021.07.20 |



