1.NLG란?
Natural Language Generation (자연어 생성)
- 시스템 계산 결과를 자연어로 자동으로 생성하는 자연어 처리 기술분야로 주어진 정보(이미지, 텍스트..)를 기반으로 정보 축약, 보강, 재구성을 하는 task를 가집니다.
좋은 자연어 생성의 기준
- 적절성: 생성된 문장이 모호하지 않고 원래의 input text의 의미와 일치해야 함
- 유창성: 문법이 정확하며 어휘를 적절하게 사용해야 함
- 가독성: 적절한 지시어, 접속사 등을 사용하여 문장의 논리 관계를 고려하여 생성해야 함
- 다양성: 상황이나 대상에 따라 표현을 다르게 생성해야 함
NLG 기본 알고리즘 : Decoding Algorithms
- Language Model은 특정 time-step까지의 words sequence가 주어졌을 때, 해당 time-step 이후의 word를 확률분포를 구성하여 예측(predict)합니다.
- Language Model 이 예측을 할 때, 구성한 확률분포에서 다음에 올 word를 결정해야 하고 이 때 사용하는 것이 Decoding Algorithms입니다.
(1) Greedy Decoding
각 step에서 구성한 확률분포 결과 중 가장 가능성이 높은 단어를 선택하여 다음 단어로 사용하는 알고리즘입니다.
다음 단어로 선택된 단어는 다음 단계의 입력으로 사용됩니다. 이러한 과정을 <END> 토큰이 생성될 때까지 시행합니다.
<장점> 한 단계에 한 단어만 선택하면 되기 때문에 매우 빠릅니다.
<단점> backtracking이 불가하여 출력 시퀀스에 오류를 포함하기 쉽고 연쇄적인 반응이 일어납니다. 또한 출력이 전반적인 context를 고려한 결과가 아닙니다.

(2) Beam Search
greedy decoding의 확장된 형태로 사용자가 설정한 후보군 수(k개)에 따라 후보군(k개)을 만들어서 확률을 tracking합니다.
greedy decoding과 다르게 특정 단어의 확률값만 고려하는 것이 아니라 부모로부터 뻗어나온 갈래의 누적확률을 고려해서 절대값이 작은 단어를 따라 문장이 생성됩니다.
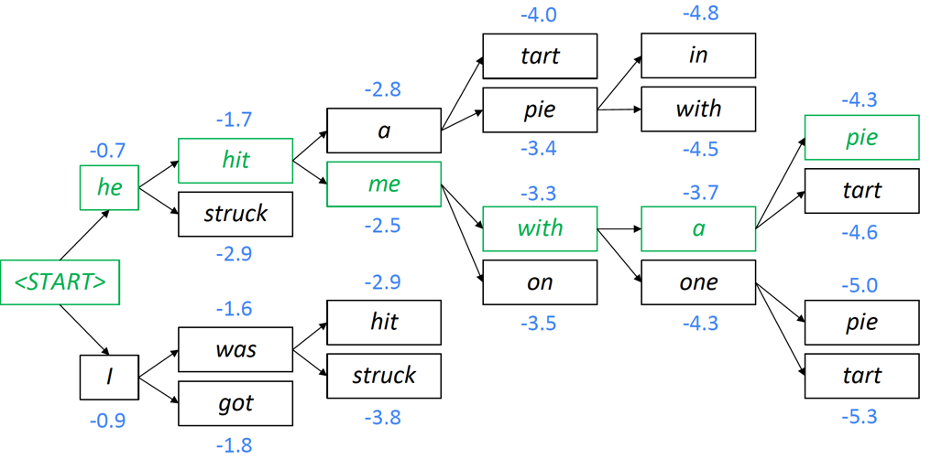
누적확률
- 그림의 파란색 수치는 누적확률입니다.
- 예측확률의 범위는 0.0 ~ 1.0입니다. 누적확률을 위해 계속해서 예측 확률이 곱해지면서 점점 값이 작아집니다.
- 점점 작아지는 값을 크고 다루기 편하게 유지 하기 위해 log를 취하기 때문에 누적확률이 마이너스로 표기 됩니다.
- 확률이 낮을 수록 절대값이 큰 값을 가지게 됨으로 누적확률은 절대값이 작은 값을 채택합니다.
원리 이해 예시
아래 그림을 보면서 이해하면 좋습니다.
K=3 라고 설정할때,
1. <start> 토큰이 먼저 입력되고 입력으로 나온 확률 분포 중 상위 3개를 뽑습니다.
2. 'a','l','the'가 입력되었을 때 나오는 예측값의 확률분포 중 상위 3개를 뽑습니다.
3. 출력된 'cat','dog' ... 'horse' 단어에서 누적확률 중 상위 3개를 뽑습니다.
4. <eos> 토큰이 입력될 때까지 k개의 후보군을 출력하고 그 중에서 누적확률을 고려하여 k개만을 남겨놓는 순서를 반복해서 진행합니다.


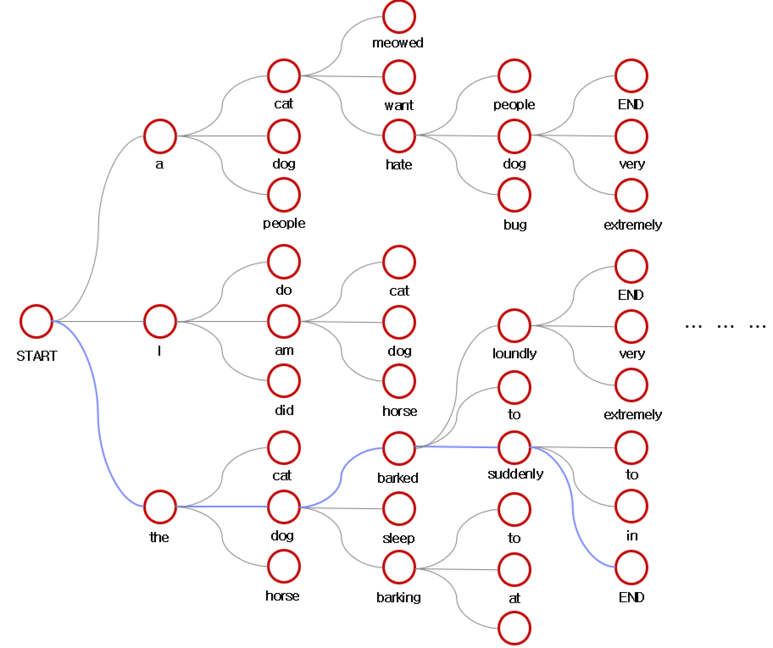

Beam size k의 영향
- Low k → greedy decoding과 유사해집니다. 주제와는 가깝지만 성립하지 않는 문장입니다.
- High k → greedy decoding의 문제점 해결. 알맞고 안전한 응답이나 포괄적이고 관련성이 적은 문장입니다. 지나치게 큰 k 값은 오히려 BLEU 점수 감소를 야기합니다.
(3) Sampling-based Decoding
Beam size가 커져도 생성되는 문장이 일반적(generic)이지 않게 하기 위한 방법입니다.
greedy decording과 다른 점은 가장 높은 확률을 무조건 채택하는 방식을 버리고 확률값에 따라 랜덤확률로 선택될 수 있게 함으로써 랜덤성을 여합니다.
예를들어 'i', 'the', 'dog' 와 같은 단어들이 각각 0.5, 0.3, 0.2의 확률값을 가졌을 때
- greedy decording : 'i' 선택
- Sampling-based Decoding : 0.5, 0.3, 0.2의 확률로 랜덤하게 선택되게 진행
pure sampling과 top-n sampling, top-p sampling의 방식이 있습니다.
- Pure Sampling
pure sampling은 각 단계마다 확률 분포를 토대로 랜덤으로 골라 다음 단어로 사용하는 방법입니다. Greedy decoding과 비슷하지만 argmax 대신 random으로 뽑은 sample을 사용한다는 차이점이 있습니다.
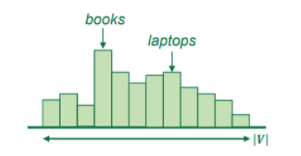
- Top-N Sampling
pure sampling처럼 완전 random한 샘플링 대신 확률이 큰 top-n개의 단어 중에서 랜덤으로 샘플을 고릅니다. 따라서 n이 클수록 다양하지만 risky 해지고, n이 작을수록 광범위하지만 안전한 결과를 출력합니다. 마찬가지로 n이 1인 경우에는 greed search, n이 전체 개수 인 경우에는 pure sampling이 됩니다.

- Top-P Sampling
누적 확률이 p 이상이 되는 최소한의 집합으로부터 샘플링을 하게 하는 방법입니다.
2. Text Abbreviation ( 텍스트 축약 )
Summarization 요약(수요가 많음)
- Abstractive : 본문에 없는 텍스트로 요약을 도출
- Extractive : 본문 내용 추출 요약 - 문장간의 중요도를 측정
- 포괄적 방식(generic summary) : 이용자에 상관없이 해당 문서 저자의 견해를 요약 제시
- 질의 기반 방식(query-based summary) : 특정 사용자의 관심사항에 중점을 두고 요약, 문서 검색 이나 개인화된 정보여과를 위한 환경에서 중요성 증대
- single-document summarization : 하나의 document를 summary하는 방식
- multi-document summarization : 여러 document의 정보를 통합해 하나로 summary하는 방식
- Pre-neural Summarization : 3개의 파이프라인으로 구성됩니다.
(1) Content selection : 포함할 주요 문장을 선택합니다.
- sentence scoring function이나 그래프 기반 알고리즘을 사용할 수 있습니다.
*sentence scoring function은 topic keyword의 유무를 tf-idf로 계산하거나 문서에서 해당 문장이 어느 위치에 나타나는지를 고려하는 방식
*그래프 기반 알고리즘은 문장을 노드로 하여 각 문장 쌍들 사이의 edge에 문장 간 유사도를 가중치로 넣어 어떤 문장이 중요한지 찾는 방식
(2) Information Ordering : 선택된 문장들을 중요도에 따라 순서대로 나열
(3) Sentence Realization : 요약문 생성 - Neural Summarization : seq2seq와 attention을 사용하여 문서요약을 하기 시작.
- Sequence-to-sequence 모델은 기계 번역에서 많이 연구 되어온 모델로, RNN(Recurrent Neural Network)을 이용하여 입력 문장의 의미를 함축하는 context vector를 만들고(encoding), 이를 다시 다른 RNN을 통하여 출력 문장을 생성(decoding)하는 방법입니다.
- Attention mechanism은 Sequence-to-sequence 모델의 디코딩(decoding) 과정에서 각 시간별 출력을 예측할 때 입력 열에서 해당 출력을 결정하는데 필요하다고 판단되는 입력 시퀀스의 hidden state를 참조하여 사용하는 방법입니다.
- 단점으로 디테일을 포착하기 어렵고 고유명사의 출력 확률이 떨어지며, 희소한 단어들의 경우에는 out-of-vocabulary(OOV)문제가 발생(해결을 위해 Copy 메카니즘이 필요함)합니다.
- 계산학적 접근법
- 하향식 (top-down) 접근법 : 사용자의 요구에 맞는 내용 추출/요약, 질의 기반 방식(query-based summary)에 해당
- 상향식 (bottom-up) 접근법 : 해당 문서의 내용 파악, 포괄적 방식(generic summary)에 해당
Summarization Evaluation
BLEU와 ROUGE는 모두 생성된 문장과 실제 정답 문장이 얼마나 비슷한지를 계산하는 지표입니다.
BLEU : 모델이 생성한 문장이 얼마나 실제 정답 문장에 등장했는지를 계산하는 precision 기반, 모든 n-gram에 대한 경우의 결과를 하나로 합쳐서 하나의 평가 수치를 도출 // machine translation에 주로 사용
ROUGE : 실제 정답 문장이 얼마나 모델이 생성한 문장에 등장하는지 계산하는 recall을 기반, n-gram에 대해 따로따로 평가 수치를 얻어 출력 // summarization에 주로 사용
Question generation
본문에 있는 내용으로 질문을 생성(level에 따른 문제를 다르게 생성)
Distractor generation
오지선다의 선택지에서 정답 외에 오답을 생성(데이터 증강)
3. Text Expansion ( 부족한 정보를 추가 )
short text expansion
정보를 추가, 데이터 길이를 확장
Topic to essay generation
키워드로 문장을 생성
4. Text Rewriting
문서의 형태를 변형
Style Transfer
- 긍정 - 부정 변형
- 활용 : 데이터 증강, 문체 변화
Dialogue Generation
페르소나를 가진 대화 생성
Dialogue 형식
- Task-oriented dialogue
- Assistive: 고객 서비스, 추천 제공, 질의 응답, …
- Co-operative: 두 agent가 하나의 태스크를 함께 해결
- Adversarial: 두 agent가 대화를 통해 태스크에서 경쟁 - Social dialogue
- Chit-chat
- Therapy
5. 모델 구성 아키텍처
-인코더 디코더 구조(RNN seq2seq, Transformer)
-Copy and pointing
Copy mechanism은 Sequence-to-sequence 모델의 디코딩 과정에서 문장을 생성할 때 앞에서 언급한 필요한 어휘가 출력 사전 (output vocabulary)에 없는 문제(Out-of-Vocabulary)와 고유명사들의 출력 확률이 작아지는 문제를 해결하기 위해 고안된 방법으로 출력에 필요한 어휘를 입력 열에서 찾아 출력 없이 복사(copy)하는 사용하는 방법입니다.
Copy mechanism은 attention mechanism과 유사한 형태의 copy attention을 별도로 두어, 디코딩 과정에서 각 시간별 출력 어휘를 예측할 때 출력 사전에 있는 어휘들의 확률과 함께 입력 열 중에서 copy attention 점수가 가장 높은 어휘를 그대로 출력할 확률도 함께 계산합니다.
*출처 : https://www.koreascience.or.kr/article/CFKO201612470014629.pdf
-GAN(Generative Adversarial Network)
-Memory Network
-GNN(Graph Neural Network)
-External Knowledge