데이터 통계 - 3 (신뢰구간 설정과 ANOVA)
신뢰구간과 ANOVA에 대해 설명 하기 전에 이해를 도울 수 있도록 기초 설명을 한다.
큰 수의 법칙 ( Law of large numbers )
sample 데이터의 수가 커질 수록, sample의 통계치는 점점 모집단의 모수와 같아진다.
중심극한정리 ( Central Limit Theorem, CLT )
Sample 데이터의 수가 많아질 수록, sample의 평균은 정규분포에 근사한 형태로 나타난다.
신뢰구간
신뢰도가 95% 라는 의미는 표본을 100번 뽑았을때 95번은 신뢰구간 내에 모집단의 평균이 포함된다.
즉, 신뢰구간이 95%->99%가 된다면 99%의 확률로 해당 구간에 평균이 포함되어 있을 것이다.
그러나 신뢰구간이 넓어짐에 따라 해당 되는 값들이 너무 많아 유의미한 결과를 얻기는 힘들다.
또한 표본의 수가 많아질수록 데이터가 많아져서 신뢰구간은 점점 좁아진다.
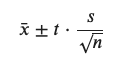
x̄ = 표본의 평균
t = t-value
s = 표본의 표준편차
n = 표본의 개수
- t * s / √n = 표준오차(Standard Error of Mean, SEM)
** 표본의 평균 - 표준오차 < 신뢰구간 < 표본의 평균 + 표준오차
참조)
Z-distribution : 평균은 0 , 분산은 1인 표준정규분포. - 신뢰구간 설정 시 x̄ +- z(1.96) * 𝜎(모집단 표준편차) / √n
T-distribution : 표준정규분포보다 양측 tail을 두껍게 변형한 것으로 표본의 크기가 충분하지 않을 때 z분포 대신 많이 쓰인다.
자유도(df)가 커질수록 z분포와 같게 된다. - 신뢰구간 설정시 모집단의 표준편차를 모를 경우 t를 사용하여 신뢰구간을 구함.
문제는 모집단의 평균과 표준편차를 모른다는 점으로 그래서 표본집단에 대한 평균과 표준편차를 사용하여 신뢰구간을 구한다.
from scipy import stats
def confidence_interval(data, confidence = 0.95):
"""
주어진 데이터의 표본 **평균**에 대한 신뢰구간을 계산.
기본 값으로 t-분포와 양방향 (two-tailed), 95%의 신뢰도를 사용합니다.
입력 값 :
data - 여러 개로 이루어진 (list 혹은 numpy 배열) 표본 관측치
confidence - 신뢰구간을 위한 신뢰도
반환 되는 값:
(평균, 하한, 상한구간)으로 이루어진 tuple
"""
data = np.array(data)
mean = np.mean(data)
n = len(data)
# std / sqrt(n)
stderr = stats.sem(data)
# Standard Error of Mean (https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.sem.html)
# s / sqrt(n)
# length_of_one_interval
interval = stderr * stats.t.ppf( (1 + confidence) / 2 , n - 1) # ppf : inverse of cdf
return (mean, mean - interval, mean + interval)
# cdf -> t 를 넣으면 %
# ppf -> % 를 넣으면 t
# 1 + 0.95 / 2 -> 0.975
# (1 - 0.95) / 2 -> 0.025from scipy.stats import t
# 표본의 크기
n = len(sample)
# 자유도
dof = n-1
# 평균의 평균
mean = np.mean(sample)
# 표본의 표준편차
sample_std = np.std(sample, ddof = 1)
# 표준 오차
std_err = sample_std / n ** 0.5 # sample_std / sqrt(n)
CI = t.interval(.95, dof, loc = mean, scale = std_err) # https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.t.html
print("95% 신뢰구간: ", CI)
ANOVA (ANalysis Of VAriance; 분산 분석)
여러 그룹간의 평균의 차이가 통계적으로 유의미 한지를 판단하기 위한 검정방법
특징 1. 집단 평균값 의 분산이 클수록 그리고, 2. 집단 내 분산이 작아질수록 평균의 차이가 분명해집니다.
Multiple Comparision
3개의 표본을 각각 2개씩 짝을 묶어서 비교를 하면 안될까 싶지만 각각 표본에서 생길 수 있는 오차 5% = 𝛼이 서로 비교를 통해 점점 오차확률이 커짐으로 한꺼번에 비교할 수 있는 방법이 필요하다.
ANOVA를 위한 전제조건
여러 그룹들이 하나의 분포에서부터 왔다 라는 가정
그를 위한 지표 F-statistic
F-statistic는 F = 𝑉𝑎𝑟𝑖𝑎𝑛𝑐𝑒−𝑏𝑒𝑡𝑤𝑒𝑒𝑛−𝑔𝑟𝑜𝑢𝑝 / 𝑉𝑎𝑟𝑖𝑎𝑛𝑐𝑒−𝑤𝑖𝑡ℎ−𝑖𝑛−𝑔𝑟𝑜𝑢𝑝

k는 클래스 수 , n은 데이터 수 , SS(between) = 클래스별 평균 분산 , SS(tot) = 전체 분산
(참조 https://tensorflow.blog/f-%EA%B0%92-%EC%9C%A0%EB%8F%84%EC%8B%9D/)
즉, F값이 높다는 것은
- 분자(다른 그룹끼리의 분산)는 크고, 분모 (전체 그룹의 분산)는 작아야 할겁니다.
- 즉 다른 그룹끼리의 분포가 다를 것이다 라는 가정이 붙는거죠.
일원분산분석(One-way ANOVA)과 이원분산분석(Two-way ANOVA)
1.일원분산분석(One-way ANOVA)
종속변인은 1개이며, 독립변인의 집단도 1개인 경우입니다. 한가지 변수의 변화가 결과 변수에 미치는 영향을 보기 위해 사용
from scipy.stats import f_oneway
f_oneway(그룹1, 그룹2, 그룹3)