
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- AARRR
- AWS builders
- 스타터스부트캠프
- NLU
- 그로스해킹
- pytorch
- 스타터스
- 토스
- 부트캠프후기
- 취업부트캠프
- 유데미큐레이션
- 데이터도서
- NLP
- 사이드프로젝트
- BERT
- 특성중요도
- 딥러닝
- 그래프
- 임베딩
- sql정리
- 유데미코리아
- MatchSum
- 알고리즘
- SLASH22
- 유데미부트캠프
- 추천시스템
- 취업부트캠프 5기
- 서비스기획부트캠프
- 서비스기획
- SQL
- Today
- Total
다시 이음
추천시스템 - Matrix Factorization(MF) 본문
추천을 위한 다양한 알고리즘의 분류로 메모리 기반 알고리즘 , 모델 기반 알고리즘이 있습니다.
앞에서 알아본 협업 필터링이 메모리 기반 알고리즘이며 추천을 위한 데이터를 모두 메모리에 가지고 있으면서 추천이 필요할 때마다 이 데이터를 사용해서 계산을 하여 추천하는 방식입니다.
모델 기반 알고리즘은 데이터로부터 추천을 위한 모델을 구성한 뒤에 이 모델만을 저장하고 실제 추천할때 이 모델을 사용하여 추천하는 방식입니다.
이번 포스트에서 알아볼 행렬요인화(Matrix Factorization) 추천방식이 대표적인 모델 기반 알고리즘입니다.
| 메모리 기반 알고리즘 | 모델 기반 알고리즘 | |
| 장점 | - 모든 데이터를 메모리에 저장하고 있어 데이터를 충실히 사용한다. - 개별 사용자의 데이터에 집중하여 개별 사용자의 행동분석을 할 수 있다. |
- 웹사이트에서 빠른 반응이 가능하다. - 전체 사용자의 평가 패턴으로부터 모델을 구성하여 개별 사용자의 행동분석에서 잘 드러나지 않는 패턴을 확인 할 수 있다. |
| 단점 | - 웹사이트에서 사용하기에는 계산시간이 너무 오래 걸린다. | - 모델을 만드는 과정에서 계산이 많이 필요하다. |
1. Matrix Factorization 방식의 원리
행렬요인화 방식은 이전 협업 필터링에서 사용하던 사용자x아이템 으로 구성된 하나의 행렬을 사용자 잠재요인행렬과 아이템 잠재요인행렬 2개의 행렬로 분해하는 방법입니다.
- 사용자x아이템 2차원 행렬 = R = M(사용자)xN(아이템) 크기
- 사용자 잠재요인 행렬 = P = M(사용자) x K(잠재요인 개수) 크기
- 아이템 잠재요인 행렬 = Q = K x N(아이템) 크기
- 식 : R = P x Q.transpose => R^
- R^은 예측치이며 최대한 R에 가까운 값을 가지도록 하는 것이 목표
예를 들어 사용자 잠재요인(P)는 사용자별 장르 선호도를 나타내며 아이템 잠재요인(Q)는 아이템별 장르 성격을 나타낸다고 할때에 표기된 장르 점수를 통해 어떤 영화가 어떤 사용자 취향에 맞는지 예상이 가능합니다.
2. SGD(Stochastic Gradient Descent) 을 사용한 MF 알고리즘
MF 알고리즘의 핵심은 주어진 R행렬을 P,Q 행렬로 분해하는 것입니다.
이 알고리즘은
(1) 잠재요인의 개수 K를 정합니다.
(2) 주어진 K에 따라 P, Q행렬을 만들고 초기화합니다.
(3) 주어진 P, Q 행렬을 통해 R^ 예측치를 구합니다.
(4) R에 있는 실제 평점에 R^ 예측 평점을 비교해서 오차를 구하고 오차를 줄이기 위해 P,Q의 값을 수정합니다.
(5) 전체 오차가 미리 정해진 기준값 이하 혹은 미리 정해진 반복 횟수에 도달할 때까지 (3)으로 돌아가서 반복합니다.
여기서 (4) 오차를 수정하는 방법으로 가장 일반적인 방법은 SGD 입니다.
2-1. 오차 수정하는 방식
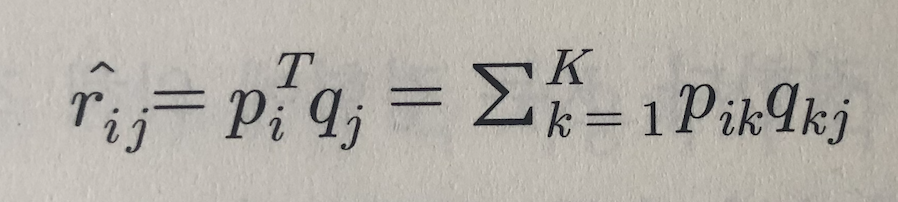
1. e(ij)는 예측 오차로 실제값에서 예측값을 뺀것입니다.

2. 정확도 지표인 MSE, RMSE를 향상시키기 위해 오차(e(ij))의 제곱을 최소화 해야합니다.

3. 위의 식은 가중치 업데이트식과 같이 p,q에 대해 편미분을 하여 생성되는 결과입니다.
<< r(ij)는 p(ij)와 q(ij)를 행렬연산하여 만들어지는 값이기 때문에 p(ik)값으로 미분할때 q(kj)값이 튕겨나오게 됩니다. >>

4. (2)번의 식을 가중치 업데이트식에 적용하여 생성된 식입니다.
(3)번 까지의 식이 MF의 기본 원리입니다.
이 후에 나오는 식은 과적합을 방지하기 위하여 정규화를 추가하고 사용자나 아이템에 있는 경향성(평가가 높거나 낮은 경향)을 제외하기 위한 식으로 개선됩니다.

베타는 정규화 정도를 결정하는 정규화 계수입니다.

5. (3)번 식에서 과적합을 방지하기 위해 정규화 항을 추가한 업데이트 식을 도출합니다.
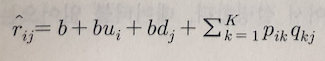
6. (base) 식에서 경향성을 고려하기 위해 경향성(bias)를 분리하여 나타낸 식이 (6)번 식입니다.
경향성을 분리하는 이유는 경향성을 제외하고 분석하는 것이 더 정확하기 때문입니다.
b = 전체 평균
bu(i) = 전체 평균을 제거한 후 아이템 i의 평가 경향( 아이템 i의 평균과 전체 평균 차이 )
bd(j) = 전체 평균을 제거한 후 아이템 j의 평가 경향 ( 아이템 j의 평균과 전체 평균 차이 )
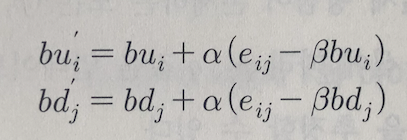
7. (6)번 식을 사용하여 편미분 과정을 거치면 평가 경향을 구하는 식을 완성할 수 있습니다.
최종적으로 (5), (7)번 식이 SGD 방법을 사용한 MF의 P,Q를 구하는 최종식입니다.
2. MF 기본 알고리즘
2-1. 주요 하이퍼 파라미터
- K : 잠재요인(latent factor)의 개수
- alpha : learning rate(학습률)
- beta : 정규화 계수
- iteration : SGD 연산 시에 반복 횟수
- verbose : SGD의 중간 학습과정을 출력할 것인가
2-2. 알고리즘 진행 순서
1. 기본 MF 알고리즘 클래스 선언
2. 손실함수(RMSE) 함수 정의
3. 훈련 함수 정의
- P,Q 행렬을 평균 0, 표준편차 1/K인 정규분포를 가지는 난수로 초기화
- 편향(bias) bu, bd ,b 변수를 0으로 초기화
- SGD 함수 호출
- SGD로 업데이트된 P,Q,bu,bd를 사용하여 RMSE 계산
4. 평점 예측하는 함수 정의
5. 위의 알고리즘 식을 사용한 SGD 함수 정의
2-3. 최적의 파라마터 찾기
잠재요인 개수 K가 늘릴 수록 다양한 패턴을 학습할 수 있어 정확도가 높아집니다. 그러나 반대로 너무 커진다면 과적합이 발생하기 쉽습니다.
3. MF와 SVD
SVD는 데이터를 3개의 행렬로 분해해서 이를 학습하고 3개의 행렬을 사용하여 원래의 행렬을 재현하는 기법입니다.
R행렬(mxn 크기) => U행렬(mxm크기) * ∑행렬(mxn크기) * V.transpose행렬(nxn 크기)
SVD 기법은 원래 행렬을 재현하는 데에는 뛰어나지만 행렬에 없는 값을 예측하는 데에 문제가 있습니다.
사용자가 평가하지 않은 아이템에 대해서 null 표시를 할 수 없는 것인데요. null값으로 대치할 경우 다시 하나의 행렬로 재현할 때 null값으로 대치한 부분은 0에 가깝게 재현되어 예측의 의미가 없습니다.
그러나 MF 알고리즘은 P,Q를 학습할 때에 0인 값을 빼고 연산을 하여 행렬에서 값이 빠져있는 null 부분도 상당히 정확하게 예측이 가능합니다.
'채우기 > 추천 시스템' 카테고리의 다른 글
| 추천 시스템 - Neural Collaborative Filtering 논문 리뷰 (0) | 2023.01.04 |
|---|---|
| Factorization Machines(FM) (0) | 2022.10.11 |
| 추천 시스템 - 협업 필터링 (0) | 2022.09.06 |
| 추천 시스템 - 시퀀셜 (0) | 2022.07.14 |
| 추천 시스템 기초 (0) | 2022.07.13 |
