
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- AARRR
- SLASH22
- 스타터스
- pytorch
- sql정리
- 유데미큐레이션
- NLU
- 그래프
- 서비스기획
- 알고리즘
- 유데미코리아
- 사이드프로젝트
- 부트캠프후기
- 서비스기획부트캠프
- NLP
- 데이터도서
- 토스
- SQL
- 스타터스부트캠프
- 특성중요도
- 유데미부트캠프
- AWS builders
- 임베딩
- 추천시스템
- MatchSum
- 취업부트캠프 5기
- 그로스해킹
- BERT
- 취업부트캠프
- 딥러닝
- Today
- Total
다시 이음
트리 기반 모델 - 4 모델선택(Model Selection) 본문
Model Selection
오늘은 어떤 문제에 대해 어떤 모델을 선택해야 할지에 대한 이야기를 해볼거에요.
결론부터 말하자면 어떤 알고리즘이 어떤 상황에서 더 좋다는 정해진 게 없습니다.
적용해 봐야 아는 것입니다.
다만 어느 정도 특정 알고리즘이 뛰어난 성능을 발휘하는 경우를 경험적으로 인지하고 이를 먼저 적용해 보면서 최적 모델을 찾습니다.
그렇기 때문에 우리는 교차검증이라는 것을 통하여 모델 선택의 문제를 해결할 수 있습니다.
교차검증(Cross-validation)
교차검증이란, 머신러닝/딥러닝 평가에 필수적으로 사용되는 방법으로 데이터를 통한 모델을 설계한 후 모델을 검증하는 단계라고 볼 수 있습니다. 다시 말해 모델을 추정하는 데 사용되지 않았던 새로운 데이터를 예측하는 일반화 능력을 테스트하는 방법입니다.
교차검증을 사용하는 이유?
- 학습에 사용가능한 데이터가 충분하다면 문제가 없겠지만, 훈련세트의 크기가 모델학습에 충분하지 않을 경우 문제가 될 수 있습니다.
- 검증세트 크기가 충분히 크지 않다면 예측 성능에 대한 추정이 부정확할 것입니다.
교차검증의 종류
1. hold-out 교차검증
우리는 이전 포스팅까지 데이터를 훈련/검증/테스트 세트로 나누어 학습을 진행해 왔습니다.
그것과 같이 훈련/검증/테스트 세트를 임의로 중복되지 않게 나누어 학습 및 검증을 실행하는 것입니다.
2. k-fold cross-validation(CV)
k-fold cross-validation은 데이터를 k개로 등분하여 k개의 집합에서 k-1 개의 부분집합을 훈련에 사용하고 나머지 부분집합을 테스트 데이터로 검증하게 됩니다.

파이썬의 sklearn 라이브러리에서 cross_val_score를 이용하면 쉽게 적용할 수 있습니다.
# cross_val_score를 이용한 교차검증 적용
from sklearn.model_selection import cross_val_score
k = 3 #(k 겹의 개수)
scores = cross_val_score(pipe(모델이름), X_train, y_train, cv=k,
scoring='neg_mean_absolute_error'(평가지표 이름))
print(f'MAE ({k} folds):', -scores)
위의 코드에서는 score의 기본을 MAE로 설정하였습니다.(scoring파라미터를 변경함으로써 다른 지표도 확인 가능합니다.)

궁금증 타임) neg_mean_absolut_error를 사용했는데 왜 mean_absolut_error를 사용안하고 negative를 사용해요??
sklearn에서는 수치가 높은 것을 성능이 좋다고 판단합니다.
그렇기 때문에 일반적인 MAE를 사용할 경우, MAE의 수치가 높으면 오차가 크다는 것으로 실제는 성능이 낮다고 판단하지만 sklearn에서는 성능이 높다고 생각하기 때문에 negative 수치로 설정을 해줍니다.
위의 cross_val_score과정에서는 출력된 수치기 때문에 큰 영향을 끼치지 않지만 곧 살펴볼 gridsearchCV나 randomizedsearchCV에서는 score가 결과에 영향을 끼치는 만큼 negative를 사용하고 있습니다.
하이퍼파라미터 튜닝
머신러닝 모델을 만들때 중요한 이슈는 최적화(optimization)와 일반화(generalization) 입니다.
- 최적화는 훈련 데이터로 더 좋은 성능을 얻기 위해 모델을 조정하는 과정이며, ( bias를 낮추고 variance를 높힌다.)
- 일반화는 학습된 모델이 처음 본 데이터에서 얼마나 좋은 성능을 내는지를 이야기 합니다. ( variance를 낮추고 bias를 높힌다.)
모델의 복잡도를 높이는 과정에서 훈련/검증 세트의 손실이 함께 감소하는 시점은 과소적합(underfitting) 되었다고 합니다.
이 때는 모델이 더 학습 될 여지가 있습니다. 하지만 어느 시점부터 훈련데이터의 손실은 계속 감소하는데 검증데이터의 손실은 증가하는 때가 있습니다. 이때 우리는 과적합(overfitting) 되었다고 합니다.
이상적인 모델은 과소적합과 과적합 사이에 존재합니다.
한가지 파라미터에 대한 검증곡선,훈련곡선 그래프를 통해서 살펴볼게요.
# 참조 검증곡선, 훈련곡선 그리기
import matplotlib.pyplot as plt
from category_encoders import OrdinalEncoder
from sklearn.model_selection import validation_curve
from sklearn.tree import DecisionTreeRegressor
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
DecisionTreeRegressor()
)
depth = range(1, 30, 2)
ts, vs = validation_curve(
pipe, X_train, y_train
, param_name='decisiontreeregressor__max_depth'
, param_range=depth, scoring='neg_mean_absolute_error'
, cv=3
, n_jobs=-1
)
train_scores_mean = np.mean(-ts, axis=1)
validation_scores_mean = np.mean(-vs, axis=1)
fig, ax = plt.subplots()
# 훈련세트 검증곡선
ax.plot(depth, train_scores_mean, label='training error')
# 검증세트 검증곡선
ax.plot(depth, validation_scores_mean, label='validation error')
# 이상적인 max_depth
ax.vlines(5,0, train_scores_mean.max(), color='blue')
# 그래프 셋팅
ax.set(title='Validation Curve'
, xlabel='Model Complexity(max_depth)', ylabel='MAE')
ax.legend()
fig.dpi = 100
위의 접은 글 안에 있는 코드를 실행시키면 max_depth를 기준으로 아래와 같은 그래프가 나옵니다.

현재의 그래프에서 이상적인 모델은 파란선으로 표현된 max_depth를 5로 했을 때입니다.
검증곡선의 오차수치가 감소하길 멈춘 시기이며 그 이후는 훈련곡선의 오차가 커지면서 과적합된다는 걸 알 수 있습니다.
이렇게 여러개의 파라미터에 대한 최적값을 찾아 하이퍼파라미터를 튜닝한다면 좋은 성능을 낼 수 있겠죠.
그렇다면 파라미터의 최적값을 찾는 방법은 뭐가 있을까요?
하이퍼파라미터는 모델 훈련중에 학습이 되지 않는 파라미터입니다. 그래서 사용자가 직접 정해주어야 합니다.
현실적으로 하이퍼파라미터를 수작업으로 정해주는 것은 어렵습니다. 최적의 하이퍼파라미터 조합을 찾아주는 도구를 사용해야 합니다.
sklearn에 하이퍼파라미터 튜닝을 도와주는 좋은 툴이 두 가지 있습니다.
- GridSearchCV: 검증하고 싶은 하이퍼파라미터들의 수치를 사용자가 정해주고 그 조합을 모두 검증합니다.
- RandomizedSearchCV: 검증하려는 하이퍼파라미터들의 값 범위를 사용자가 지정해주면 무작위로 값을 지정해 그 조합을 모두 검증합니다.
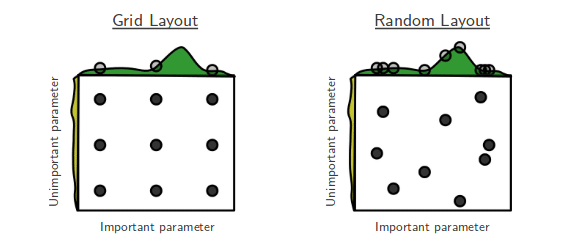
1. Randomized Search CV
#릿지회귀에 randomized search cv 적용
from sklearn.model_selection import RandomizedSearchCV
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True)
, SimpleImputer()
, StandardScaler()
, SelectKBest(f_regression)
, Ridge()
)
# 튜닝할 하이퍼파라미터의 범위를 지정해 주는 부분
dists = {
'simpleimputer__strategy': ['mean', 'median'],
'selectkbest__k': range(1, len(X_train.columns)+1),
'ridge__alpha': [0.1, 1, 10],
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50, # 50번 반복
cv=3, # 교차검증 3번
scoring='neg_mean_absolute_error',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);
#최적의 파라미터 값 보기
print('최적 하이퍼파라미터: ', clf.best_params_)
print('MAE: ', -clf.best_score_)
# rank_test_score: 테스트 순위
# mean_score_time: 예측에 걸리는 시간
pd.DataFrame(clf.cv_results_).sort_values(by='rank_test_score').T
위의 코드는 릿지회귀모델에 대해 randomized search cv를 사용하여 최적의 파라미터를 적용해본 것입니다.
dists 라는 값을 지정하여 우리는 하이퍼파라미터의 값의 범위를 지정해주었습니다.
(이 부분이 잘못 지정이 되면 오류가 생기기 쉬운데요. 정확하게 해당 메소드에 대한 하이퍼 파라미터를 파악하여 값을 지정해야합니다.)
n_iter = 반복 횟수를 지정하는 파라미터입니다.
cv = 교차검증 개수
위의 코드를 실행하면 n_iter값 * cv값의 경우를 모두 학습합니다.
scoring 설정에 유의해야합니다.
예시는 릿지회귀모델에 대한 것이기에 scoring이 MAE값으로 지정되어있지만 분류모델를 다룰 때에는 그에 맞는 평가지표(accuracy, recall, precision, f1-score)를 설정해주어야 합니다.
혹시 분류모델에 대한 평가지표에 대해 궁금하시면 이전 포스트인 https://thogood212.tistory.com/27 을 참고해주세요 ㅎㅎ
2. Grid Search CV
from sklearn.model_selection import GridSearchCV
dists = {
'simpleimputer__strategy' : ['mean'],
'randomforestclassifier__n_estimators': [100,500],
'randomforestclassifier__max_depth': [10, 15],
'randomforestclassifier__max_features': [10,20], # max_features
'randomforestclassifier__min_samples_leaf' : [10, 15]
}
glf = GridSearchCV(
pipe_1,
param_grid=dists,
scoring='f1',
cv=3,
verbose=1,
n_jobs=-1
)
Grid search cv는 설정한 하이퍼파라미터의 모든 값을 적용해보고 교차검증하는 메소드입니다.
하이퍼파라미터의 수를 위와 같이 정했을 경우 2*2*2*2 = 16에 cv=3를 곱하여 48가지를 학습합니다.
설정한 모든 파라미터의 값을 모두 학습하는 만큼 다변화해서 하면 좋은 성능을 얻을 수 있지만 계산 시간이 엄청 오래 걸릴 수도 있는 단점이 있습니다.
Refit ( 재학습 )
위에서 우리는 하이퍼파라미터의 최적값을 찾는 방법 2가지를 봤습니다.
2개의 메소드 모두 best_estimator_라는 Attribute를 지원합니다.
best_estimator_ 는 CV(교차검증)가 끝난 후 찾은 best parameter를 사용해 모든 학습데이터(all the training data)를 가지고 다시 학습(refit)한 상태입니다.
위에서 우리가 살펴본 것은 하이퍼 파라미터의 최적값을 '찾기'만 한 것입니다.
찾기만 한다고 해서 교차검증을 한 모델의 성능이 좋아지지 않습니다.
모델의 성능을 변화시켜주는 것은 하이퍼파라미터를 튜닝하여 학습하고 새로운 모델로 변경을 해주었을 때 비로소 좋은 성능을 내게 됩니다.
# 만들어진 모델에서 가장 성능이 좋은 모델을 불러옵니다.
pipe = clf.best_estimator_ (ramdomized search cv)
pipe = glf.best_estimator_ (grid search cv)
모델이 변경되어 학습까지 마쳤습니다.
해당 모델에 다시 predict를 통해 확인하세요.
# 성능 확인하기
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import f1_score
1. 회귀모델 일때
y_pred = pipe.predict(X_val)
mae = mean_absolute_error(y_val, y_pred)
print(f'테스트세트 MAE: ${mae:,.0f}')
2. 분류모델 일때
from sklearn.metrics import classification_report
y_pred = pipe.predict(X_val)
print(classification_report(y_val, y_pred))
Tip) 배운 것을 연관해서 생각해보세요.
오늘 교차검증을 배웠습니다.
어제는 분류모델에 최적의 임계값을 활용하는 방법을 배웠습니다.
그렇다면 오늘 배운 교차검증을 통하여 최적의 하이퍼파라미터를 구하고 적용한뒤에
최적의 임계값또한 찾아 적용해보시는 것은 어떨까요?
'AI 일별 공부 정리' 카테고리의 다른 글
| 실전 예측 분석 모델링 - 1 ML problems (0) | 2021.08.24 |
|---|---|
| EDA의 여러가지 방법 (0) | 2021.08.23 |
| 트리 기반 모델 - 3 Evaluation Metrics for Classification (0) | 2021.08.20 |
| 트리 기반 모델 - 2 랜덤포레스트 (Random Forests) (0) | 2021.08.18 |
| Feature Engineering - Pipe line(파이프라인) (0) | 2021.08.18 |


