
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- MatchSum
- 추천시스템
- 임베딩
- 유데미부트캠프
- 토스
- NLU
- 알고리즘
- BERT
- sql정리
- 데이터도서
- 서비스기획부트캠프
- AARRR
- pytorch
- 그래프
- 스타터스
- 부트캠프후기
- NLP
- 특성중요도
- 취업부트캠프 5기
- 유데미큐레이션
- 딥러닝
- AWS builders
- SLASH22
- 스타터스부트캠프
- 취업부트캠프
- 사이드프로젝트
- 유데미코리아
- 그로스해킹
- SQL
- 서비스기획
- Today
- Total
다시 이음
딥러닝(9) - Transformer & BERT, GPT 본문
안녕하세요.
오늘은 Transformer라는 자연어 처리 모델중 어제 알아보았던 Attention 메커니즘의 기능을 최대화 하여 사용하는 모델에 대해서 알아보려고 합니다.
Transformer 논문 : https://arxiv.org/abs/1706.03762 : Attention is All you need 라는 논문으로 트랜스포머 관련해서는 가장 유명한 논문이라고 합니다.
Transformer
트랜스포머는 RNN의 순차적으로 단어가 입력되는 방식에서 단어가 많아질 수록 연산속도가 느려지는 문제점을 보완하고자 고안되었습니다.
트랜스포머는 단어를 입력받을 때 병렬화를 사용하며 그에 따라 GPU 연산에 최적화 되어있습니다.
Transformer 구조
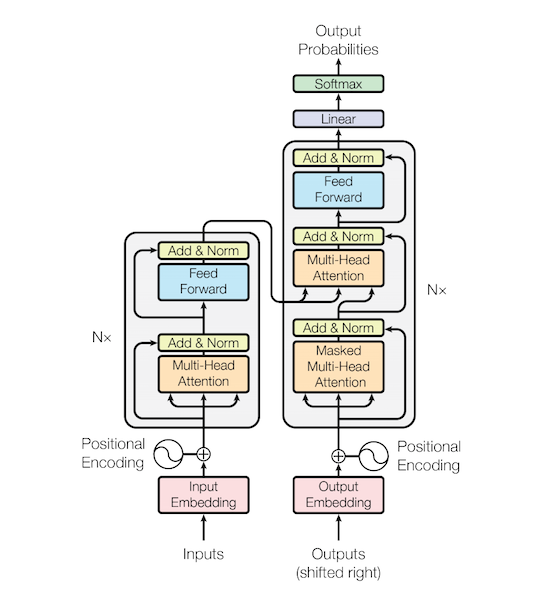
먼저 위의 그림을 설명하자면 왼쪽은 트랜스포머 안에 1개의 Encoder, 오른쪽은 1개의 Decoder 만을 시각화 한 자료입니다.
기본적인 Transformer는 6개의 Encoder와 6개의 Decoder가 모여서 구성됩니다.
구조를 하나하나씩 보면서 마지막에 전체적인 줄기를 설명해보겠습니다.
Input : Input으로는 찾을 값을 넣어줍니다. (기계번역(영어->스페인)이라면 영어가 입력값이 되겠죠)
여기서 RNN과 다르게 트랜스포머에서는 병렬화를 위해 모든 단어 벡터를 동시에 입력을 받습니다. (RNN에서는 순차적으로 한 단어씩 입력하여 가중치를 업데이트했습니다.)
이렇게 한꺼번에 입력이 되기 때문에 해당 입력값에 대한 순서정보가 부재합니다.
이를 보완하기 위해 Positional Encoding 과정을 거쳐 순서정보를 제공합니다.
1. Encoder
1) Self-Attention
트랜스포머의 기본적인 메커니즘이자 그림상의 multi-head attention을 이해하기 위해 기본적인 구조인 self-attention에 대해서 알아보겠습니다.
self-attention은 번역하려는 문장 내부 요소의 관계를 잘 파악하기 위해서 자기자신에게 attention 메커니즘을 적용합니다.
앞서 배운 Attention과의 차이점으로는
RNN이 포함되어 있지 않은 구조에서 쿼리, 키, 밸류 값을 만들어야하기 때문에 가중치 벡터인 wq,wk,wv의 값을 처음에 랜덤값으로 설정하여 업데이트 하는 과정을 거칩니다.
좀더 설명을 하자면 x1이라는 단어가 들어갔을 때 x1과 wq가 연산되어 query1이, x1과 wk가 연산되어 key1이, x1과 wv가 연산되어 value1이 생성됩니다.
이렇게 만들어진 쿼리, 키, 밸류 값을 통해 어제 배운 attention과 같이 연산 과정을 거칩니다.
1. 쿼리 벡터와 키 벡터를 내적합니다.
2. 이렇게 나온 score를 query,key,value 벡터의 차원 dk의 제곱근으로 나눠줍니다. (계산값을 안정적으로 만들어 주는 과정)
3. softmax를 사용하여 쿼리에 해당하는 단어와 다른 단어의 관계의 비율을 나타냅니다.
4. 도출된 비율에 각 value를 곱하고 모두 더해주면 z값이 결과로 나오면서 self-attention과정은 마무리가 됩니다.
위와 같은 연산과정을 거치면 x1에 대한 z1값이 나옵니다.
앞에서 트랜스포머는 입력값을 병렬화 하여 한번에 입력받는다고 했습니다.
그렇기 때문에 그 다음 단어인 x2,x3,x4,,,도 같이 연산을 거치면 z2,z3,z4,,, 와 같은 값들이 도출 됩니다.
이렇게 z가 병렬적으로 생성되어 처리하는 과정을 Multi-Head Attention 이라고 합니다.
2) Multi-Head Attention
self-attention과정을 병렬적으로 실행하는 방법입니다.
위에서 살펴봤듯이 z1,z2,z3,z4,,,과 같이 여러개 생성된 z인 값들을 말그대로 이어붙입니다.
예를들어서 z1,2,3,4의 크기가 모두 2x4의 크기를 가진다면 이어붙인 z의 크기는 2x16인 것입니다.
이렇게 구한 z에 wo라는 가중치 벡터를 곱해주면 최종적으로 Z가 완성됩니다.
이 Z의 크기는 처음에 encoder에 입력되어 토큰화가 진행된 X의 크기와 같습니다.
3) Layer Normalization & Skip Connection
layer normalization은 batch normalization과 비슷합니다. 학습이 빠르고 잘되게 해줍니다.
Skip Connection은 역전파 과정에서 그래디언트를 항상 1이상으로 유지하기 때문에 정보가 손실되지 않게 해주는 역할을 합니다.
4) Feed Forward Neural Network (FFNN)
활성화함수로 relu를 사용하는 간단한 신경망입니다.
이렇게 Encoder1에서 1~4의 과정을 거친 결과값(Z1)는 그 다음 인코더(Encoder2)로 들어가는 입력값이 됩니다.
Z1을 입력받은 Encoder2는 연산과정을 거쳐 Z3를 결과값으로 내놓고 그 다음엔 반복과정이 이루어집니다.
이렇게 Encoder6까지의 연산을 끝마치면 Z6의 값을 활용하는 것이 아니라 Encoder6에서 업데이트된 키, 밸류 값만이 디코더에 전달이 되어 활용되게 됩니다.
2. Decoder
이제부터는 Decoder의 구조를 살펴보겠습니다.
Input : Input으로는 찾을 값을 넣어줍니다. (기계번역(영어->스페인)이라면 스페인어가 입력값이 되겠죠)
Positional Encoding 과정을 거쳐 순서정보를 제공합니다.
1) Masked Self-Attention
디코더 블록에서 사용되는 특수한 Self-Attention입니다.
단어 전체를 병렬화 하여 입력하였던 encoder의 self-attention과 다르게
타깃 단어 이후 단어를 보지 않고(Masking) 단어를 예측해야 합니다.
이렇게 사용되는 마스킹은 앞에 나온 self-attention에 과정중 1,2과정은 똑같이 진행을 하고
softmax 적용 전에 마스킹해야 하는 부분에 -10억 과 같은 매우 작은 수를 더해줍니다.
이렇게 적용된 수는 softmax 함수 적용되면 0의 값이 됩니다.
이렇게 도출된 값은 Z로 이 다음에 오는 Encoder-Decoder Attention에서 쿼리값으로 사용됩니다.
2) Encoder-Decoder Attention
앞서 Encoder 부분에서 나온 결과값인 Key와 Value값을 가져와서 사용합니다.
Query값은 Masked self-attention에서 도출된 결과값(Z)로 사용합니다.
연선과정은 Multi-Head self-Attention과 같습니다.
3) FFNN
활성화함수로 relu를 사용하는 간단한 신경망입니다.
위의 1~3까지의 과정이 n번 이루어지는 하나의 Decoder입니다.
GPT(Generative Pre-trained Transformer)
GPT는 트랜스포머의 변형 모델이면서 사전학습된 언어 모델인데요.
사전학습(Pre-trained)이란 대량의 데이터를 통해 미리 학습화는 과정입니다.
Label이 지정되어있지 않은(Unsupervised/비지도학습) Pre-training을 하고,
Label을 지정해준 (supervised/지도학습) Fine-Tuning을 통해 모델에 우리가 하고자하는 태스크에 특화된(Task specific) 데이터를 학습시킴으로써 여러가지 Task를 수행할 수 있도록 조정할 수 있습니다.
GPT구조
GPT의 구조는 Transformer에서 인코더를 뺀 디코더만 12개를 사용한 구조를 가지고 있습니다.
거기서도 인코더값이 없어 Encoder-Decoder Attention 부분을 제외한 부분만 디코더가 가지고 있습니다.
❄️ 여기서 디코더만 사용한다는 뜻은, 디코더의 역할만을 한다는 뜻이 아닌 self-Attention의 디코더부분만으로 모든 역할을 대신한다는 뜻입니다.
BERT(Bidirectional Encoder Representation by Transformer)
BERT는 트랜스포머의 인코더만을 사용하여 문맥을 양방향(Bidirectional)으로 읽어냅니다.
GPT와 같이 사전학습과 Fine-Tuning을 사용하는 부분은 같습니다. 하지만 다른 방식을 사용합니다.
- 사전학습 방식
1)MLM(Masked Language Model)
BERT는 사전 학습 과정에서 레이블링 되지 않은 말뭉치 중에서 랜덤으로 15%가량의 단어를 마스킹합니다.
이렇게 마스킹한 단어를 예측하면서 학습을 진행하는데요.
그런데 GPT에서는 타겟으로 잡은 단어의 오른쪽 부분은 모두 마스킹하는 걸 기억하시나요?
BERT는 그와 다르게 "단어1 단어2 단어3 [ ] 단어4 단어5" 과 같이 타겟값만 마스킹하고 그외에 양방향 모두의 단어정보를 사용합니다.
이럴때 왼쪽의 문맥만을 파악하여 학습한 GPT모델보다 양쪽으로 모든 문맥을 파악하여 좀더 정확한 의미를 파악하는 모델이 될 수 있습니다.
2) NSP(Next Sentence Prediction)

아래 설명할 단어 입력시에 Special Token을 사용하여 하나의 문장을 2개의 텍스트로 나누고, 이렇게 나누어진 텍스트가 왼쪽문장에서 오른쪽 문장으로 이어진 텍스트인가를 파악하여 맞는 경우 "IsNext", 아닌경우 "NotNext"로 나오도록 학습합니다.
이러한 학습방법을 통해 문장과 문장 사이의 관계를 학습할 수 있도록 함으로써 질의응답(QA), 자연어 추론(NLI) 등 문장 관계를 이해해야만 하는 복잡한 태스크에서 좋은 성능을 나타내는 역할을 하였습니다.
-BERT의 Special Token ([CLS], [SEP])과 입력 벡터
GPT와는 입력 부분에서도 다른점이 존재합니다.
먼저 Special Token을 보면 원래는 단순히 <sos>(단어의 시작을 알림), <eos>(단어의 끝을 알림) 으로만 이루어있는 구조지만,
단어의 시작을 [CLS]로, [SEP]은 텍스트를 두번으로 나누기때문에 중간에 한번 마지막에 한번씩 들어갑니다.
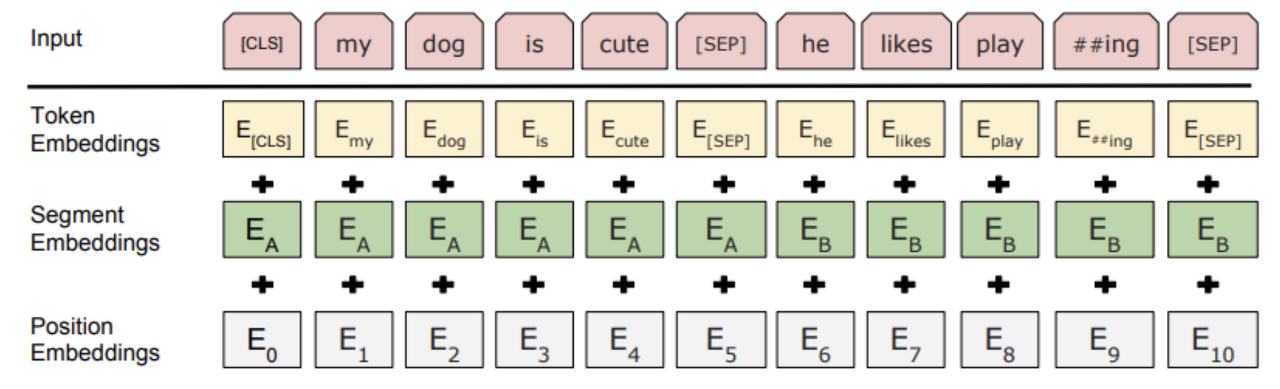
입력벡터도 한번 볼까요?
원래는 토큰 임베딩과 포지션 임베딩 두개가 존재하지만 CLS를 통해 텍스트를 두개로 나누는 정보를 알려주기 위해 Segment Embeddings라는 임베딩 벡터값을 추가로 가집니다.
GPT&BERT 이후의 모델은? (PostBERT)
1. 모델을 크게크게 : 사전학습이 많이 될수록 더 좋은 성능이 나타나는 것을 이용하여 엄청나게 방대한 데이터를 사용해 덩치를 키운 모델들이 나오고 있습니다.
2. 단점을 보완하자 : GPT와 BERT의 단점을 보완하여 두 모델의 구조를 혼용(Auto-Encoder(양방향 인식 BERT) + Auto-Regressive(GPT 순차적으로 자연어를 생성)하여 BART라는 모델이 나오기도 하고, BERT의 Masking방법에 변화를 줘 보완한 SpanBERT, RoBERTa이 있습니다.
3. 너무 크기가 커졌다 최적화를 통해 경량화 하자
4. Fine-Training이 없어도 어디든 이용될 수 있는 범용성을 키우자
참고 : https://wikidocs.net/31379
https://yngie-c.github.io/nlp/2020/07/01/nlp_transformer/
'AI 일별 공부 정리' 카테고리의 다른 글
| 딥러닝(11) - Image Segmentation & Data Augmentation & Object Recognition (0) | 2021.11.03 |
|---|---|
| 딥러닝(10) - Convolutional Neural Networks(합성곱 신경망) (0) | 2021.11.01 |
| 딥러닝(8) - RNN(Recurrent Neural Network, 순환 신경망) (0) | 2021.10.27 |
| 딥러닝(7) - Distributed Representation(분산표현) (0) | 2021.10.27 |
| 딥러닝(6) - 자연어 처리(NLP, Natural Language Processing) (0) | 2021.10.25 |



