
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 유데미큐레이션
- pytorch
- 취업부트캠프 5기
- 추천시스템
- 딥러닝
- 데이터도서
- AARRR
- 알고리즘
- BERT
- 서비스기획
- 스타터스
- 특성중요도
- SLASH22
- sql정리
- 유데미부트캠프
- 스타터스부트캠프
- 서비스기획부트캠프
- NLP
- SQL
- 사이드프로젝트
- MatchSum
- NLU
- 그래프
- AWS builders
- 유데미코리아
- 그로스해킹
- 부트캠프후기
- 취업부트캠프
- 토스
- 임베딩
- Today
- Total
다시 이음
Week 1-3. NLG 과제 본문
NLG sub task - Extractive summarization task(내용 추출 요약)
문제 정의
수많은 데이터가 생겨나는 요즘, 인간의 능력으로 유의미한 내용만을 선택하여 확인하기엔 정보를 모두 받아들일 수 없을 뿐만아니라 시간이 부족합니다. 이를 해결하기 위해 summarization을 통해 요약문의 문장이나 단어구들은 전부 원문에 있는 문장 사용하여 유의미한 정보만을 추출 요약하여 사용할 수 있습니다.
데이터셋 소개 : CNN / Daily Mail, DebateSum
CNN / Daily Mail
- CNN 및 Daily Mail 웹사이트의 뉴스 기사에서 질문으로 생성되었고 스토리는 시스템이 빈 채우기 질문에 답할 것으로 예상되는 해당 구절로 생성되었습니다. 저자는 이러한 웹사이트에서 한 쌍의 구절과 질문을 크롤링, 추출 및 생성하는 스크립트를 출시했습니다.
- 데이터 구조
코퍼스에는 스크립트에 정의된 대로 286,817개의 훈련 쌍, 13,368개의 검증 쌍 및 11,487개의 테스트 쌍이 있습니다. 훈련 세트의 소스 문서는 평균 29.74개의 문장에 걸쳐 766개의 단어를 가지고 있으며 요약은 53개의 단어와 3.72개의 문장으로 구성됩니다.

DebateSum
- 데이터 구조
187328개의 토론 문서, 논쟁(추상적인 요약 또는 쿼리로 생각할 수도 있음), 단어 수준의 추출 요약, 인용 및 주제 연도별로 구성된 관련 메타 데이터로 National Speech and Debate Association 내 경쟁자들이 수집한 데이터를 사용하여 만들어졌습니다.
SOTA 모델 소개 : HAHSum, Longformer
HAHSum
Hierarchical Attentive Heterogeneous Graph for Text Summarization
공동 추출 및 구문 압축을 기반으로 하는 단일 문서 요약을 위한 신경 모델.
모델은 문서에서 문장을 선택하고, 구성 요소 구문 분석을 기반으로 가능한 압축을 식별하고, 신경 모델을 사용하여 이러한 압축에 점수를 매겨 최종 요약을 생성합니다. 학습을 위해 오라클의 추출-압축 요약을 구성하고 함께 학습합니다.
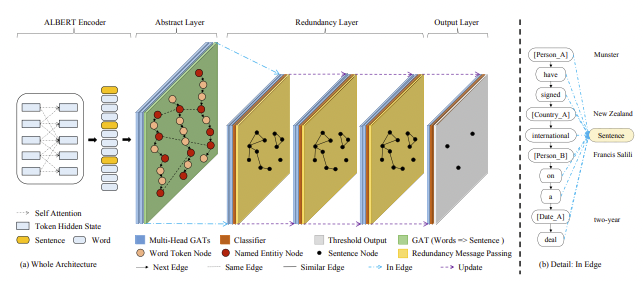
ALBERT 인코더와 추상화 층, redundancy layer의 구조를 가진다.
원리
아래 순서와 같이 계층적으로 구조 파악 및 분해
1. 긍정 명사구
2. 관계절과 부사절
3. 명사구의 형용사구 및 부사구
4. 명사구의 일부로서의 동명사 동사구
5. 월요일과 같은 특정 구성의 전치사구
6. 괄호 및 기타 괄호 안의 내용
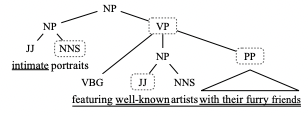
- 논문 키워드 : Graph structure , Problem Definition, Graph Attention Network, ALBERT Encoder
Longformer
Transformer의 self-attention은 인풋 시퀀스 길이의 제곱에 비례하여 메모리와 계산량이 늘어납니다.
따라서 이는 많은 NLP task를 해결하는 데에 문제가 되었고 BERT 또한 512로 시퀀스를 제한하는 등, 긴 문서에 대해서 처리하기 힘듭니다.
attention 메커니즘의 계산량의 문제점을 지적하고 이를 인풋 시퀀스의 길이에 선형적으로 비례하는 계산량을 가진 attention 메커니즘을 제안하였습니다.

Sliding Window (b, 이하 '윈도우 방식'으로 표기)
토큰 근처의 w개의 고정된 크기의 윈도우에 대해서만 attention 값을 계산하고, 윈도우를 벗어나 멀리 떨어진 토큰에 대해서는 attend하지 않는 방식입니다.
Dilated Sliding Window (c, 이하 '확장된 윈도우 방식'으로 표기)
그림과 같이 d개씩 토큰을 건너뛰며 윈도우를 듬성듬성하게 확장하여 구성하는 방법입니다. d를 작게 설정하더라도 기본적인 윈도우 방식보다 훨씬 넓은 영역에 대한 representation을 생성할 수 있습니다.
Global Attention (d)
텍스트 분류, 질의응답과 같은 태스크에서는 [CLS], [SEP]과 같은 스페셜 토큰을 사용합니다. 이러한 토큰의 경우 전체적인 문맥에 대해 attend하도록 하는 것이 유리하고, 따라서 논문에서는 미리 선택해 둔 스페셜 토큰의 위치에 대해서는 global attention을 적용하여 전체 토큰에 대해 attend 합니다.
- 논문 키워드 : Attention Pattern, Frozen RoBERTa Weights
'Pre_Onboarding by Wanted(자연어 처리)' 카테고리의 다른 글
| Pytorch - 기초 구조 (0) | 2022.03.01 |
|---|---|
| Week1-4. 리뷰 긍정부정 판별 모델 설정 프로세스 (0) | 2022.02.24 |
| NLG 란? (0) | 2022.02.23 |
| Week 1-2 NLU 과제 (4) | 2022.02.22 |
| NLU란? (0) | 2022.02.22 |


