
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- NLU
- 토스
- 스타터스부트캠프
- 사이드프로젝트
- 서비스기획
- MatchSum
- 취업부트캠프 5기
- 취업부트캠프
- pytorch
- sql정리
- NLP
- AARRR
- AWS builders
- 그래프
- 부트캠프후기
- 알고리즘
- 유데미큐레이션
- 유데미코리아
- 유데미부트캠프
- 서비스기획부트캠프
- 데이터도서
- SLASH22
- 임베딩
- 스타터스
- 특성중요도
- BERT
- 추천시스템
- 그로스해킹
- 딥러닝
- SQL
- Today
- Total
다시 이음
데이터 통계 -2 (추가적 가설 검정) 본문
올바른 가설 검정위한 조건
- 독립성 : 두 샘플그룹이 연결성이 있는지
- 등분산성 : 비교할 대상의 scale이 비슷한지
- 정규성 : 정규분포와 일치하는지 - 정규분포는 평균 µ 을 기준으로 좌우로 대칭
어제 공부한
one sample t-test는 특정한 그룹의 평균에 예측값이 같은지 다른지를 검증하였고,
two sample t-test는 특정한 그룹들의 평균을 비교하여 서로간의 크고 작음을 검증하였다.
(서로 다른 그룹과 비교(독립성0), 같은 그룹이 어떤 행동을 했나 안했나(독립성X,정규성0)으로 구분지을 수 있다.)
그중 독립성이 가정된 샘플에 대해 정규성에 만족한다면 모수적 방법, 정규성이 불만족하다면 비모수적 방법을 사용한다.
Non-Parametric Methods(비모수적 방법)
모집단이 특정 확률 분포 (normal과 같은)를 따른다는 전제를 하지 않는 방식.
parameter estimation이 필요하지 않기 때문에 non-parametric이라고 부름
- Categorical 데이터를 위한 모델링
- 혹은 극단적 outlier가 있는 경우 매우매우 유효한 방식
- distribution free method라고 부르기도 함.
- Chisquare
- Spearman correlation
- Run test
- Kolmogorov Smirnov
- Mann-Whitney U
- Wilcoxon
- Kruskal-Wallis 등
카이제곱검증(Chi-squared test)
Chi-squared test는 표본집단의 분포를 비교할 때 선택하는 방법 , 특히 명목척도 자료의 분석
* 내가 이해한 것 :
- 카이를 제곱한 이유 : 비교를 할때 차이를 극명하게 보여주기 위해 - 제곱때문에 그래프가 0부터 시작한다.
- 그래프를 보고 알 수 있는 것 : x값은 카이제곱통계값, 그래프 라인에 해당하는 값은 카이제곱값을 적분하여 p-value를 나타낸 것이다.
- 즉, 카이검정 통계값이 커질 수록 유의수준에 가까워진다. 그러나 반대로 p-value 값은 작아질 수록 유의수준에 가까워진다.
- 통계값이 커질 수록 귀무가설을 기각하는 기각역(p)에 들어가게 되고, p-value 값은 0.05이하로 가면 귀무가설을 기각하는 기각역(p)에 속한다.
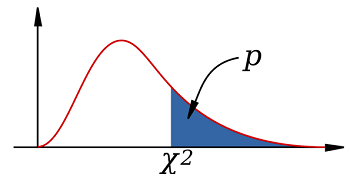
1) 카이제곱 적합도 검정( one sample chi-squared test )
주어진 데이터가 균등한 분포를 나타내고 있는지
귀무가설 : 예측치와 비슷할 것이다
대립가설 : 예측치와 다를것이다.
예시 ) 주사위를 던졌을 때 각 1~6까지의 값이 예측치(평균)과 비슷할 것인지.
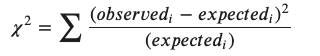
observed = 관측 데이터
expected = 예측 데이터 = observed 관측데이터의 총합 / 관측데이터 개수
파이썬에서 검정하기
from scipy import stats
from scipy.stats import chisquare
#데이터 array입력해서 p-value 확인하기
chisquare(데이터 array, axis=None)
#chisquare 메소드 없이 함수로 풀이하기
total_obs = np.sum(obs) # 관측데이터 총합
exp = total_obs / obs.count() # 기대값 구하기
x1 = (obs-exp)**2/exp
x2 = np.sum(x1) #카이제곱 구하기
stats.chi2.pdf(x2, df(=자유도)) # 카이제곱 값과 자유도를 넣으면 p-value 확인가능
1 - stats.chi2.cdf(x2, df ) #동일2) 카이제곱 독립성 검정( two sample chi-squared test )
두 변수간의 연관성을 파악하는 방법
귀무가설 : 연관성이 없을 것이다.(독립적이다.)
대립가설 : 연관성이 있을 것이다. (독립적이지 않다.)
카이제곱을 구하는 식은 같다.
그러나, Expected value는
| (A+B)*(A+C) / T | (A+B)*(B+D) / T | A+B | |
| (A+C)*(C+D) / T | (B+D)*(C+D) / T | C+D | |
| A+C | B+D | T |
즉, 각 데이터마다 예측값이 모두 다르다.
from scipy import stats
from scipy.stats import chi2_contingency
chi2 = chi2_contingency(데이터프레임, correction = True or False)
# 따로 카이제곱을 구할 필요 없이 관측데이터 값으로만으로 확인가능
# 함수를 통해 카이제곱값 구하기
obs = np.array([[9, 2], [13, 3]])
total_obs = np.sum(obs)
exp = np.array([[(9+2)*(9+13), (9+2)*(2+3)], [(13+3)*(9+13), (13+3)*(2+3)]])
exp = exp / total_obs # 예측값을 구하기 위해 총합을 나눔
squared = np.power(obs - exp, 2) # 카이제곱 값구하는 식 대입
x2 = np.sum(squared / exp) # 카이제곱 값 구함
'AI 일별 공부 정리' 카테고리의 다른 글
| 데이터 통계 - 4 (베이즈 정리) (0) | 2021.07.20 |
|---|---|
| 데이터 통계 - 3 (신뢰구간 설정과 ANOVA) (0) | 2021.07.19 |
| 데이터 통계 -1 (샘플링과 가설 검정) (0) | 2021.07.15 |
| pandas trick 및 데이터 다듬기 (0) | 2021.07.12 |
| pandas 기초 이해 (0) | 2021.07.10 |

