
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 서비스기획
- sql정리
- 사이드프로젝트
- 데이터도서
- SQL
- 유데미부트캠프
- 스타터스부트캠프
- NLU
- 유데미큐레이션
- 특성중요도
- pytorch
- BERT
- 딥러닝
- 취업부트캠프 5기
- AARRR
- 알고리즘
- 취업부트캠프
- AWS builders
- NLP
- 토스
- 부트캠프후기
- 그래프
- 스타터스
- 추천시스템
- 그로스해킹
- 임베딩
- SLASH22
- 유데미코리아
- MatchSum
- 서비스기획부트캠프
- Today
- Total
다시 이음
Pytorch - Autograd 이해하기 본문
안녕하세요.
오늘은 딥러닝 학습방법에 역전파 방법에서 Pytorch에서 제공하는 Autograd 기능을 설명하려고 합니다.
Pytorch의 기본적인 딥러닝 학습방법을 이해하는 데 좋음으로 읽어보면 좋을 것 같습니다.
Autograd
먼저 Pytorch의 Autograd 기능에 대해 알아보겠습니다.
Autograd는 PyTorch의 자동 미분 엔진입니다.
Autograd가 어떤 기능을 하는지에 대해서 설명하기 위해서는 기본적인 딥러닝의 학습방법에 대해 간단하게 정리할 필요가 있습니다.
1. 딥러닝은 신경망으로 이루어져있고, 그 신경망은 가중치(weight)+bias(편향)의 매개변수를 텐서(pytorch.tensor)형태로 가지고 있습니다.
2. 딥러닝의 학습은 2단계로 순전파, 역전파가 있습니다.
3. 순전파는 최대한 정답을 맞추기 위해 신경망은 추측을 합니다.
4. 역전파는 순전파에서 생긴 추측값과 라벨값을 비교하고 손실함수를 정의, 손실함수의 값(gradient기울기)이 점차 낮아지는 방향(경사하강법)으로 학습(최적화)합니다.
역전파 방법의 학습을 위해서는 경사하강법(gradient descent)이 필요하고 이를 위해서는 미분을 통해 gradient를 알아야합니다.
경사하강법은 optimizer(옵티마이저)에 의해 최적화 되는 방식을 사용하여 학습을 하게 됩니다.
순서대로 보자면
#손실함수 구하기
loss = CrossEntropyLoss(예측값, 라벨값)#역전파 하기
loss.backward()#경사하강법 적용하기 (옵티마이저 업데이트)
optim.step() # 경사하강법(gradient descent)입니다.
Pytorch 공식문서에서 Pytorch에서 딥러닝 학습이 진행되는 방법에 대해 가져왔습니다.
연산 그래프(Computational Graph)
개념적으로, autograd는 데이터(텐서)의 및 실행된 모든 연산들(및 연산 결과가 새로운 텐서인 경우도 포함하여)의 기록을 Function객체로 구성된 방향성 비순환 그래프(DAG; Directed Acyclic Graph)에 저장(keep)합니다.
이 방향성 비순환 그래프(DAG)의 잎(leaf)은 입력 텐서이고, 뿌리(root)는 결과 텐서입니다. 이 그래프를 뿌리에서부터 잎까지 추적하면 연쇄 법칙(chain rule)에 따라 변화도를 자동으로 계산할 수 있습니다.
순전파 단계에서, autograd는 다음 두 가지 작업을 동시에 수행합니다:
- 요청된 연산을 수행하여 결과 텐서를 계산하고,
- DAG에 연산의 변화도 기능(gradient function) 를 유지(maintain)합니다.
역전파 단계는 DAG 뿌리(root)에서 .backward() 가 호출될 때 시작됩니다. autograd 는 이 때:
- 각 .grad_fn 으로부터 변화도를 계산하고,
- 각 텐서의 .grad 속성에 계산 결과를 쌓고(accumulate),
- 연쇄 법칙을 사용하여, 모든 잎(leaf) 텐서들까지 전파(propagate)합니다.
다음은 지금까지 살펴본 예제의 DAG를 시각적으로 표현한 것입니다. 그래프에서 화살표는 순전파 단계의 방향을 나타냅니다. 노드(node)들은 순전파 단계에서의 각 연산들에 대한 역전파 함수들을 나타냅니다. 파란색 잎(leaf) 노드는 잎 텐서 a 와 b 를 나타냅니다.
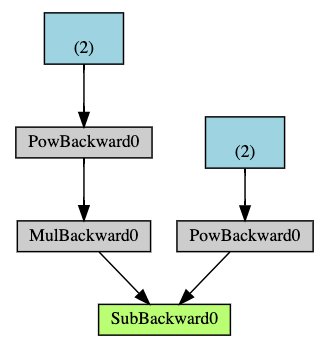
Autograd의 실행원리
이제 순서를 알았으니 Autograd의 실행원리를 알아보겠습니다.
이에 들어가기 앞서 무조건 미분, 편미분, 체인룰 에 대해 검색해보고 내용을 알아야 합니다.
torch.tensor에는 getattr 메소드를 활용하여 'requires_grad', 'is_leaf', 'grad_fn', 'grad'속성을 불러올 수 있습니다.
- 'requires_grad' : True - 해당 파라미터를 업데이트하는 것을 허용, False - 해당 파라미터에 역전파가 진행 되지만 파라미터를 상수처리하여 업데이트되지 않음
-사용자가 True로 정의한 경우에 해당 파라미터의 파생된 텐서,파라미터의 경우에 자동으로 requires_grad=True가 됩니다. - 'is_leaf' : requires_grad가 사용자에 의해 True로 설정된 경우에 is_leaf가 True로 설정, 그러나 파생된 텐서, 파라미터의 경우에는 requires_grad가 True임에도 is_leaf = False로 설정됩니다.
- requires_grad와 is_leaf가 모두 True 인 경우에만 Gradient를 계산하고 grad에 Gradient를 저장합니다. - 'grad_fn' : backward()를 호출하면 기존의 계산식을 거꾸로 거슬러 올라가면서 Gradient를 계산합니다. 이때 거슬러 올라가면서 호출해 주는 함수의 정보가 Tensor의 grad_fn에 저장됩니다. 살펴보면 is_leaf가 True라서 거슬러 올라갈 필요가 없는 경우에 grad_fn이 존재하지 않고, is_leaf가 False라서 거슬러 올라갈 필요가 있는 경우에 grad_fn이 존재합니다.
- 'grad' : backward()시 self의 gradient를 계산한 Tensor가 됩니다.
계산된 gradient를 포함하여, 이후 호출에서 backward()에 대한 gradient를 누적합니다.
예시) 출처 : https://teamdable.github.io/techblog/PyTorch-Autograd
import torch
def get_tensor_info(tensor):
info = []
for name in ['requires_grad', 'is_leaf', 'retains_grad', 'grad_fn', 'grad']:
info.append(f'{name}({getattr(tensor, name, None)})')
info.append(f'tensor({str(tensor)})')
return ' '.join(info)
x = torch.tensor(5.0, requires_grad=True)
y = x ** 3
z = torch.log(y)
print('x', get_tensor_info(x))
print('y', get_tensor_info(y))
print('z', get_tensor_info(z))
## 사이에 메소드를 넣어 사용합니다.생략가능
##
z.backward()
print('x_after_backward', get_tensor_info(x))
print('y_after_backward', get_tensor_info(y))
print('z_after_backward', get_tensor_info(z))출력값 예시)
x requires_grad(True) is_leaf(True) retains_grad(None) grad_fn(None) grad(None) tensor(tensor(5., requires_grad=True))
y requires_grad(True) is_leaf(False) retains_grad(None) grad_fn(<PowBackward0 object at 0x7f7822fe19e8>) grad(None) tensor(tensor(125., grad_fn=<PowBackward0>))
z requires_grad(True) is_leaf(False) retains_grad(None) grad_fn(<LogBackward object at 0x7f7822fe19e8>) grad(None) tensor(tensor(4.8283, grad_fn=<LogBackward>))
x_after_backward requires_grad(True) is_leaf(True) retains_grad(None) grad_fn(None) grad(0.6000000238418579) tensor(tensor(5., requires_grad=True))
y_after_backward requires_grad(True) is_leaf(False) retains_grad(None) grad_fn(<PowBackward0 object at 0x7f7822fe19e8>) grad(None) tensor(tensor(125., grad_fn=<PowBackward0>))
z_after_backward requires_grad(True) is_leaf(False) retains_grad(None) grad_fn(<LogBackward object at 0x7f7822fe19e8>) grad(None) tensor(tensor(4.8283, grad_fn=<LogBackward>))
기본 설명
어려워보이지만 하나하나 해석해보면 어렵지 않습니다.
y,z 변수는 x변수에서 파생된 값입니다.
backward() 후 출력값을 보면 x는 is_leaf=True, 파생된 y,z는 is_leaf=False입니다.
그래서 grad는 x.grad만 존재합니다.
Gradient값은 아래 그림과 같이 계산됩니다.
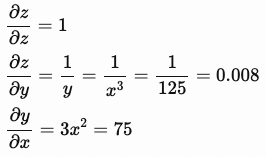
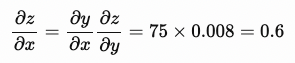
x.grad = 0.6
y.grad = 0.008
z.grad = 1
여기서 중요한 점은 Gradient를 계산하기 위해서는 역전파가 필요하고 requires_grad가 True로 설정되어야 계산이 가능하다는 점입니다.
함수
예시를 보시면 backward() 과정 전에 ## 사이에 함수를 사용할 수있는 자리를 남겨두었습니다.
Autograd에는 어떤 함수가 있고 사용하면 어떤 결과를 가져오는지 정리해보겠습니다.
- retain_grad()
y.retain_grad()
z.retain_grad()
z.backward()
## 출력값 차이 y,z의 grad를 확인하세요
x_after_backward requires_grad(True) is_leaf(True) retains_grad(None) grad_fn(None) grad(0.6000000238418579) tensor(tensor(5., requires_grad=True))
y_after_backward requires_grad(True) is_leaf(False) retains_grad(True) grad_fn(<PowBackward0 object at 0x7ff0783929e8>) grad(0.00800000037997961) tensor(tensor(125., grad_fn=<PowBackward0>))
z_after_backward requires_grad(True) is_leaf(False) retains_grad(True) grad_fn(<LogBackward object at 0x7ff0783929e8>) grad(1.0) tensor(tensor(4.8283, grad_fn=<LogBackward>))retain_grad는 결과값과 같이 is_leaf 가 False임에도 불구하고 grad 값이 저장되도록 설정시켜줍니다.
- backward(retain_graph=True)
z.backward(retain_graph=True)
z.backward()
###출력값 차이 x값의 grad차이를 확인하세요.
x_after_backward requires_grad(True) is_leaf(True) retains_grad(None) grad_fn(None) grad(0.6000000238418579) tensor(tensor(5., requires_grad=True))
y_after_backward requires_grad(True) is_leaf(False) retains_grad(None) grad_fn(<PowBackward0 object at 0x7f2f5bf589e8>) grad(None) tensor(tensor(125., grad_fn=<PowBackward0>))
z_after_backward requires_grad(True) is_leaf(False) retains_grad(None) grad_fn(<LogBackward object at 0x7f2f5bf589e8>) grad(None) tensor(tensor(4.8283, grad_fn=<LogBackward>))
x_after_2backward requires_grad(True) is_leaf(True) retains_grad(None) grad_fn(None) grad(1.2000000476837158) tensor(tensor(5., requires_grad=True))
y_after_2backward requires_grad(True) is_leaf(False) retains_grad(None) grad_fn(<PowBackward0 object at 0x7f2f5bf589e8>) grad(None) tensor(tensor(125., grad_fn=<PowBackward0>))
z_after_2backward requires_grad(True) is_leaf(False) retains_grad(None) grad_fn(<LogBackward object at 0x7f2f5bf589e8>) grad(None) tensor(tensor(4.8283, grad_fn=<LogBackward>))원래 backward()를 두번 호출하면 오류가 발생합니다.
오류 발생 이유를 알기 위해서는 위에서 설명한 연산 그래프(Computational Graph)를 생각해야 합니다.
backward()는 실행됨과 동시에 연산 그래프에서 backward()의 실행에 필요한 각종 자원을 해제합니다.
그러나 retain_graph를 True로 설정해서 호출하면 backward() 호출에 필요한 자원을 backward() 내부에서 해제하지 않습니다.
대신 x.grad의 값을 비교해 보면 값이 다릅니다. 이것은 backward()에서 Gradient를 x.grad에 저장할 때 Gradient를 덮어쓰는 것이 아니라 기존 저장되어 있는 x.grad값에 Gradient를 더하기 때문입니다.
사용하는 이유
- mini-batch와 같이, 한 iteration에서 여러 번 backpropagate해야 할 때 유용
-언제 backpropagate을 여러번 하는가
1. loss function이 여러개여서 backpropagate 여러번해야할 때
2. NN의 head가 여러개일 때
3. GAN에서
- input과 output 사이에 모델이 두개가 있고, 각 모델을 지날 때마다 loss function을 확인하는 구조의 network라면, 첫 loss에서 retain_graph=True를 하는 방법이 있고, total_loss = loss1 + loss2를 해서 total_loss를 backward하는 방법이 있습니다.
- optimizaer를 달리 쓰고 싶거나, step-size(or learning rate)를 조정하고 싶을 때
- detach(), requires_grad_()
x = torch.tensor(5.0, requires_grad=True)
y = x * torch.tensor([2.0, 3.0, 5.0])
w = y.detach()
w.requires_grad_()
z = w @ torch.tensor([4.0, 7.0, 9.0])
## 출력값 차이 w의 grad가 저장되어있음
x_after_backward requires_grad(True) is_leaf(True) retains_grad(None) grad_fn(None) grad(None) tensor(tensor(5., requires_grad=True))
y_after_backward requires_grad(True) is_leaf(False) retains_grad(None) grad_fn(<MulBackward0 object at 0x7f68b8bf4978>) grad(None) tensor(tensor([10., 15., 25.], grad_fn=<MulBackward0>))
w_after_backward requires_grad(True) is_leaf(True) retains_grad(None) grad_fn(None) grad(tensor([4., 7., 9.])) tensor(tensor([10., 15., 25.], requires_grad=True))
z_after_backward requires_grad(True) is_leaf(False) retains_grad(None) grad_fn(<DotBackward object at 0x7f68b8bf49b0>) grad(None) tensor(tensor(370., grad_fn=<DotBackward>))이번에는 ## 사이에 사용하는 것이 아닌 텐서값에 지정하는 방법입니다.
주로 연결된 두 네트워크를 사용하지만, loss로부터 detach된 지점을 넘어 back propagate되지 않길 원할 때 사용합니다.
여기서 역전파는 w에서 멈추게 되는데 그 이후에 x,y에도 역전파를 사용하고 싶을 때에는 아래와 같이 역전파가 멈추는 다음 텐서(y)부터 다시 back propagate를 해주면 됩니다.
이때에는 꼭 이전 gradient 값을 불러와서 이어질 수 있도록 해주어야 합니다.
z.backward()
y.backward(gradient=w.grad)
- .backward(create_graph=True)
x가 변할 때 x.grad가 얼마나 변하는지(자코비안행렬) = 역전파 최종목표, x가 변할때 f()함수가 얼마나 변하는지를 구하기 위해서는 backward() 설정을 변경해주어야 합니다.
기존 backward()만 실행하고 x.grad를 살펴보면 x.grad.requires_grad과 x.grad.grad_fn이 설정되어 있지 않습니다.
즉, x.grad가 기존 Graph에서 detach된 것처럼 Graph안에 포함되어 있지 않아서 x가 변할 때 x.grad 변화량을 확인 할 수 없다는 말입니다.
그렇기때문에 create_graph=True로 설정하여 x.grad도 Graph에 포함되면서, x.grad.requires_grad가 True로 설정되고 x.grad.grad_fn도 설정됩니다.
z.backward(create_graph=True)
x_2nd_grad = torch.autograd.grad(x.grad, x)
Grad를 얻는 이유 및 과정이 궁금하신 분은 딥러닝에서 자코비안 행렬을 찾아 공부해보시거나 딥러닝 역전파에 대해 찾아보시면 도움이 됩니다.
오늘은 딥러닝에서 역전파가 이루어지는 과정, Pytorch에서 역전파 과정에 도움을 주기 위해 제공하는 Autograd 에 대한 설명과 사용법, Autograd에서 제공하는 메소드를 통한 grad를 찾는 방법에 대해서 알아보았습니다.
'Pre_Onboarding by Wanted(자연어 처리)' 카테고리의 다른 글
| Pytorch - Bert 사용하여 Fine-tuning하기 (0) | 2022.03.08 |
|---|---|
| 임베딩 (1) - Word embedding (0) | 2022.03.08 |
| Pytorch Dataset / Dataloader (0) | 2022.03.02 |
| Pytorch 모델 생성 및 layer 설정 (0) | 2022.03.02 |
| BERT 모델 임베딩 이해하기 (0) | 2022.03.01 |

