
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- NLU
- 유데미부트캠프
- 취업부트캠프
- SLASH22
- NLP
- 데이터도서
- 부트캠프후기
- 서비스기획부트캠프
- 취업부트캠프 5기
- AARRR
- 특성중요도
- 사이드프로젝트
- 서비스기획
- BERT
- AWS builders
- 그래프
- SQL
- 알고리즘
- 유데미코리아
- 토스
- 딥러닝
- 스타터스부트캠프
- sql정리
- 스타터스
- 추천시스템
- 임베딩
- MatchSum
- pytorch
- 그로스해킹
- 유데미큐레이션
- Today
- Total
다시 이음
MATCHSUM 구현하기 - 논문 정리(2) 본문
오늘은 MatchSum 논문 Extractive Summarization as Text Matching의 본문 내용을 정리하였습니다.
본문
2. Related Work(본 논문이 다루는 주제에 기존 관련 연구들을 확인하는 부분)
2.1 Extractive Summarization(추출 요약)
최근 추출 요약 연구에서 다양한 범위에서의 시도를 하고 있는데 대부분 encoder-decoder 프레임워크를 사용하는 RNN, Transformer, GNN, non-auto-regressive, auto-regressiv decoders 를 선택하고 있습니다.
이러한 모델은 sentence level에서의 추출기이며 개별적인 score 프로세스에서 최고 score 문장을 요약문으로 채택합니다. 그러나 이렇게 선택된 요약문은 최적의 요약문이 아닐 가능성이 있습니다.
강화학습을 통해서 summary-level에서의 score 방법이 요약 성능의 진보를 증명했습니다.
그러나, 이러한 노력은 auto-regressive, non-auto-regressive 구조에서만의 한계를 가지고 있습니다. 게다가 non-auto-regressive 구조에서는 the Integer Linear Programming(ILP) 방법만이 summary level score 방법입니다.
auto-regressive(AR)
자기 자신을 입력으로 하여 자기 자신을 예측하는 모델.
NLP에서는 예측 연산에 필요한 확률을 이전 단어가 주어졌을 때, 다음 단어가 나올 확률들을 모두 곱한 것으로 가정합니다.
디코더에서 주로 사용되며 한번에 한단계씩 생성하기때문에(순차적으로 각 토큰을 생성할때 이전 생성 토큰에 영향을 받음) 시간이 많이 걸리고 병렬화가 불가능한 단점이 있습니다.
non-auto-regressive(NAR)
AR connection을 제거하는 것으로 추출할 target sentence 길이에 따라 독립적인 확률을 사용하는 것을 보입니다. 이 부분에서는 본 논문에서 인용한 논문을 확인하고 업데이트 예정.
그리고 본 논문 이전에 의미론적 관점에서의 추출 요약을 개선하려고 했던 concept coverage, reconstruction, maximize semantic volume과 같은 방버도 있습니다.
2.2. Two-stage Summarization
최근에 two-stage document summarization 시스템을 구축을 시도한 논문들이 있습니다.
구체적으로 확인하자면 첫번째 스테이지는 원문의 fragment를 추출하고 두번째 스테이지에서는 추출한 fragment를 선택하거나 수정합니다.
Chen and Bansal (2018) and Bae et al. (2019)은 policy-based RL의 네트워크 구조를 활용한 hybrid extract-then-rewrite 구조를 사용하였고 Lebanoff et al. (2019); Xu and Durrett (2019); Mendes et al. (2019) 은 extract-then-compress learning패러다임의 Compressive summarization를 사용했습니다.
compressvie summarization은 콘텐츠 선택을 위해 추출기를 훈련합니다.
본 논문은 이 중 불필요한 정보를 pruning(가지치기)한 문장 추출기를 사용한 extract-then-compress 프레임워크를 사용합니다.
3. Sentence-Level or Summary-Level? A Dataset-dependent Analysis
추출 요약에서 summary level의 추출기가 sentence level의 추출기보다 좋은가?
위의 두 추출기 중 활용한 벤치마크 데이터셋에 맞게 어떤 추출기를 선택하는 것이 좋으며 이 두 추출기의 차이는 무엇일까요?
이 두가지 질문에 대한 정량적인 분석이 이루어지지 않았습니다.
이 섹션에서는 이 2가지 방법에 대한 조사를 할 것이며 실험에 사용할 sentence level의 추출기는 중복 제거 프로세스를 포함하지 않아 summary level의 추출기가 중복 제거에 미치는 영향도 추정할 수 있습니다. 특히, 이번 섹션에서 사용할 이론적인 효율성을 예측할 수 있는 분석 방법은 일반화 되어 있으며 모든 summary level 접근 방식에서 적용가능합니다.
3.1 Definition
용어 정리
하나의 문서(D)는 n개의 문장들로 구성되어 D= {s1,s2,...,sn} 로 표기합니다.
후보군 요약(Candidate summary, C)는 본문으로부터 추출한 k(k<=n)개의 문장을 포함하며 C={s1,s2,...,sk | si ∈ D} 로 표기합니다. 후보군 요약은 ROUGE score를 사용하여 연산하였습니다.
중요 요약(Gold summary, C*)는 문서 D에서 추출되었으며 C*로 표기합니다.
아래 두가지의 score 방식에서 ROUGE는 ROUGE-1, ROUGE-2,ROUGE-L 의 평균을 뜻합니다.
1) Sentence Level Score
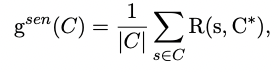
*s = 후보군 요약 안에 문장
*|C| = 문장들의 개수
이 식은 후보군 요약과 중요 요약안의 각각의 문장들간의 중첩 횟수의 평균을 구하는 방법입니다.
2) Summary Level Score

이 식은 후보군 요약 전체 문장과 중요 요약 간의 ROUGE score를 연산하는 방법입니다.
Pearl Summary
Pearl Summary는 sentence level에서는 score가 낮지만 summary level에서는 score가 높은 요약문을 뜻합니다.
Best Summary
모든 후보군 요약문 중에 Summary level score가 가장 높은 문장을 best summary 로 정의합니다.
Definition 1
Pearl summary로 후보군 요약(C)가 정의되기 위해서는 다른 후보군 요약(C')가 아래 식을 만족해야합니다.

풀이 하자면, C가 C'보다 sentence level score가 낮고 반대로 summary level score는 더 높을때 후보군요약(C)를 Pearl summary로 정의합니다.
Definition 2
요약문 C^은 Best summary가 아래 식을 만족할 때 정의됩니다.

3.2 Ranking of Best-Summary
각 문서들에서 후보군 요약을 sentence level score를 기반으로 내림차순 정렬하고 z를 best summary(C^)의 rank index로 정의했습니다.

위 그래프들은 여섯개의 벤치마크 데이터셋의 분포를 나타낸 것으로 X축은 z / 후보군 요약 개수, Y축은 best summary가 rank에 속한 비율을 나타냅니다.
풀어서 설명하면 z는 지금 sentence level score로 내림차순 정렬이 된 후보군 요약 중에 summary level score가 가장 높은 best summary의 인덱스입니다. sentence level에서 요약이 잘 되었다면 언제나 best summary는 가장 높은 index 1이 되어야 하지만 그래프를 확인하면 그렇지 않습니다.
본 논문에서는 z > 1 이면, best summary가 pearl summary 이라고 하며 z의 값이 증가할수록 (C^의 순위가 낮아질수록) sentence level score가 best summary보다 높은 다른 후보군 요약을 찾을 수 있었고 이러한 점은 sentence level의 추출기의 학습 어려움으로 뽑을 수 있다는 결과를 도출하였습니다.
3.3 Inherent Gap between Sentence-Level and Summary-Level Extractors
위의 서술된 분석으로 summary level 방법이 sentence level 방법보다 pearl summary를 더 잘 잡아낸다는 것을 알았습니다. 그러나 얼마나 향상된 모습을 데이터셋에 따라 보여줄까요?
본 논문에서는 이를 데이터셋 potential gain으로 정량화하여 확인하기 위해 하나의 지표를 정의합니다.
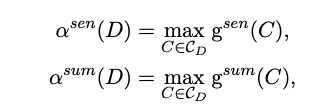
*CD = 문서(D)에서 추출한 후보군 요약
식을 설명하자면 각각 sentence level score와 summary level score가 가장 높은 값을 나타냅니다.
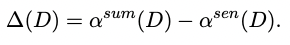



위의 식들을 사용하여 데이터셋 마다 그래프로 표현 했고 오른쪽의 데이터셋 분석자료와 비교합니다.
식 설명을 조금 곁들이자면 pearl summary는 summary level의 score와 sentence level의 score의 차이가 클수록 유의미하게 구분 될 수 있다고 파악할 수 있으며 그렇기 때문에 그 차이를 수치적으로 정량화 하여 분석하였습니다.
CNN/DM 데이터셋이 가장 높은 측정치를 기록하였고 분석자료와의 비교를 통해 Doc.(문서의 길이 평균)의 차이가 요인이라는 것을 찾았습니다.
짧은 요약문들을 가지고 있는 Reddit, XSum 데이터셋은 pearl summary가 의미론적 요약 향상에 도움이 크게 되지 않는다는 것을 알수 있고 유사하게 PubMed, Multi-News와 같은 긴 요약문을 가진 데이터셋에서는 이미 summary의 길이가 길어서 의미론적으로 중첩되는 부분을 이미 많이 가지고 있어 성능 향상에 관련성이 적다는 것을 확인하였습니다.
그러나 중간 길이의 summary(약 60 단어)는 의미있는 효과를 내었습니다.
4. Summarization as Matching
위에서 pearl summary의 효용성에 대해서 파악하였고 이번 섹션에서는 summary level의 추출을 할 수 있는 추출기를 제안합니다.
간단한 siamese-based 구조를 활용하여 어떻게 matching summarization 프레임워크를 구성하였는지 서술하겠습니다.
4.1 Siamese-BERT
siamese network 구조에서 영감을 받아 문서(D)와 후보군 요약(C)를 매칭하기 위해 Siamese-BERT 구조를 구성하였습니다.
Siamese-BERT는 2개의 BERT로 구성되어 있으며 이 모델들은 하나의 가중치를 공유하고 코사인 유사도를 활용하여 inference과정을 거칩니다.
modified BERT과 다르게 original BERT를 사용하여 문서(D)와 후보군 요약(C)의 의미있는 임베딩을 구합니다. 더이상 sentence level의 representation이 필요없기 때문입니다.
기존 BERT와 같이 top BERT layer의 [CLS]토큰의 vector를 사용합니다.
아래의 식을 사용하여 유사도 score를 측정합니다.
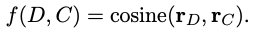
*rD = 문서(D)의 임베딩
*rC = 후보군 요약(C)의 임베딩
Siamese-BERT를 미세조정 하기 위해 손실함수로 margin-based triplet loss 를 사용하며 중요 요약(C*)는 문서 본문과 의미론적으로 가장 근접해야합니다.
그러기 위해서 손실함수에 몇가지 규칙을 적용 하였습니다.

*r1 = margin value
위의 식을 살펴보면 f(D,C) > f(D,C*) + r1 의 관계가 성립되어야 합니다.
우리는 모든 후보군 요약을 사용하여 margin value(r1)을 비교하는 pairwise margin loss 방법을 설계하였고 모든 후보군 요약들에 대하여 중요 요약(C*)와 ROUGE score를 구하여 내림차순으로 정렬하였습니다.
자연적으로 후보군 쌍이 rank 차이가 심할수록 더 큰 margin value를 가지게 되고 이를 적용하기 위해 두번째 원칙을 설계하였습니다.

*Ci = i번째에 랭크된 후보군 요약
*r2 = 좋은, 나쁜 후보군 요약문을 구별할 수 있는 하이퍼파라미터
완성된 손실함수 margin-based triplet loss의 식은 아래와 같습니다.
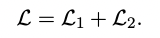
기본 아이디어는 중요 요약(Gold summary)가 높은 score를 기록하게 하는 것입니다. 그리고 동시에 부적격한 후보군 요약과 비교해서 좀더 나은 후보군 요약이 더 높은 score를 얻어야합니다.

위의 그림은 기본 아이디어를 설명한 것입니다.
inference 과정에서는 문서(D)에서 추출된 모든 후보군 요약(C)중에서 가장 좋은 요약을 찾는 작업으로 추출 요약을 공식화합니다.

4.2 Candidates Pruning
매칭 아이디어는 combinatorial explosion problem(차원의 저주와 같은 문제)에 있어서 직관적으로 보입니다.
예를 들어서 후보군 요약의 개수와 모든 후보군에게 점수를 연산하는 것이 맞는지와 같은 어려움을 줄이기 위해 pruning(가지치기) 전략을 사용합니다.
사용할 모듈은 각 문장에 중요도를 할당하고 현재 문서와 관련이 없는 문장을 pruning합니다.
prun된 문서를 D' = {s'1,s'2,..., s'ext | s'i ∈ D}로 표현합니다.
사용된 모듈은 다른 two-stage summarization에서도 많이 사용된 parameterized neural network입니다.
우리는 trigram blocking 방법(BERTEXT)을 사용하지 않은 BERTSUM을 사용했습니다.
모든 경우의 수를 고려한 문장을 pruning하고 다시 추려낸 문장을 원문에 맞게 정렬하여 사용자가 정의한 k개의 후보군 요약 세트를 구성합니다.
정리
1) sentence level과 summary level 점수를 정량화 하여 6개의 데이터셋에서 비교해본 결과 sentence level의 방법으로는 Best summary를 찾지 못하는 경우가 많았다.
2) 논문에서 정의한 pearl summary는 데이터셋에 포함된 문서 길이(단어개수)가 길수록 유효한 결과를 보이며 추출할 요약문의 길이가 짧거나 너무 길면 효과가 없어진다.
3) MATCHSUM 모델은 two-stage document summarization(extract-then-compress(match))을 사용하고 첫번째 스테이지는 원문의 fragment를 추출하고 두번째 스테이지에서는 추출한 fragment를 선택하거나 수정합니다.
- 1 stage : candidate pruning
- trigram blocking 방법(BERTEXT)을 사용하지 않은 BERTSUM을 사용
- 2 stage : Siamese-BERT
- 2개의 BERT가 하나의 가중치를 공유하며 학습하고 inference과정에서 코사인유사도를 확인합니다.
- 손실함수 margin-based triplet loss 를 사용합니다.
'AI 일별 공부 정리' 카테고리의 다른 글
| MATCHSUM 구현하기 - 세부사항 확인 및 구현 (2) | 2022.12.13 |
|---|---|
| MATCHSUM 구현하기 - 논문 정리(3) (0) | 2022.11.02 |
| MATCHSUM 구현하기 - 논문 정리(1) (1) | 2022.10.31 |
| 시계열 데이터 예측에 대하여(Forecasting: Principles and Practice)-(3) (0) | 2022.01.04 |
| 시계열 데이터 예측에 대하여(Forecasting: Principles and Practice)-(2) (0) | 2021.12.30 |
