
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 취업부트캠프
- AARRR
- AWS builders
- 그래프
- 유데미큐레이션
- 토스
- SLASH22
- 딥러닝
- BERT
- 취업부트캠프 5기
- 서비스기획부트캠프
- 알고리즘
- sql정리
- NLU
- NLP
- 특성중요도
- 그로스해킹
- 부트캠프후기
- SQL
- MatchSum
- 유데미코리아
- 임베딩
- 유데미부트캠프
- 사이드프로젝트
- 추천시스템
- 스타터스부트캠프
- 데이터도서
- 서비스기획
- 스타터스
- pytorch
- Today
- Total
다시 이음
MATCHSUM 구현하기 - 논문 정리(3) 본문
오늘은 논문 본문 마지막 부분과 결론 부분을 알아보겠습니다.
5. Experiment
5.1 Datasets
본 논문에서 제시한 프레임워크의 효용성을 알아보기 위해 아래의 벤치마크데이터셋을 활용하여 설명하려고 합니다.
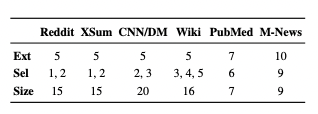
*Ext = 문서를 pruning한 후 문장의 개수
**Sel = 후보군 요약(C)을 구성하는 문장의 개수
***Size = 최종 후보군 요약의 개수
CNN/DailyMail : 뉴스 기사, 요약문 포함
PubMed : 과학 논문으로 구성, 긴 글 (본 논문에선 intro 부분을 문서로, abstract 부분을 요약으로)
WikiHow : 온라인 지식 베이스로부터 추출된 다양한 문서
XSum : 한 문장 요약 데이터셋 (기사의 주제)
Multi-News : 뉴스 요약 데이터셋, 긴 요약문
Reddit : SNS 에서 모아진 데이터셋 (TIFU-long 버전을 사용해서 body는 문서로, TL;DR 부분은 요약으로)
5.2 Implementation Details(구현 세부 사항)
- Adam optimizer 사용
- learning rate scheduler 사용
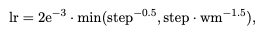
*wm = warmup step of 10,000
- batch size : 32
- r1(margin value) : 0
- r2(좋은, 나쁜 후보군 요약문을 구별할 수 있는 하이퍼파라미터) : 0.01
- 학습시간 : CNN/DM 데이터셋에서 Siamese-BERT 모델을 얻기위해 8 TeslaV100-16G GPUs를 30시간동안 학습했습니다.
- 전처리 : sample, 빈 문서 삭제, 512 token의 길이로 truncate*
*그래서 ORACLE 모델은 512token으로 잘린 데이터셋으로 연산되었습니다.
r1 < 0.05 , 0.005<r2<0.05 이면 성능에 작은 영향을 미치며, 아닐 경우에는 성능 하락에 요인이 됩니다.
아래 표에 기술된 score는 학습 중 validation set에 적용시 best performance를 보인 3개의 checkpoint를 사용하여 도출된 score의 평균을 뜻합니다.
5.3 Experimental Results
Results on CNN/DM

앞의 3개의 모델은 강력한 성능의 Baseline 모델로 일반적으로 summarization task에서 baseline으로 사용됩니다. (pruning한 문서를 사용하기 때문에 MATCH-ORACLE 점수가 상대적으로 낮습니다.)
LEAD : 전문(문서에서 앞에 위치한 몇개의 문장을 뜻함)
ORACLE : extractive model 학습에서 사용되는 groundtruth 입니다.
MATCH-ORACLE : MATCHSUM 모델을 훈련하기 위한 groundtruth입니다.
표의 두번째 섹션에서 사용된 모델 중 전체 문서에 대한 scoring을 가능하게 해주는 강화학습을 사용한 모델도 있으나 아직 sentence level의 요약 모델이기때문에 성능이 많이 향상되지 않았습니다.
Trigram Blocking은 간단하지만 신경만 모델을 기반으로 하는 모든 중복 방법보다 효과적입니다.
MATCHSUM 모델을 비교해보았을 때 BERTEXT 모델보다 향상된 성능을 보였고 encoder를 BERT-base에서 RoBERTa-base로 변환하면 더 좋은 성능을 보여줍니다.
Results on Datasets with Short Summaries

Reddit, XSum 데이터셋은 추출 요약보다는 추상적 요약 task에서 자주 사용되는 짧은 요약문을 가지는 데이터셋입니다.
여기서도 MATCHSUM 모델은 다른 추출 요약 모델보다 성능의 향상을 볼 수 있습니다.
그러나 orignal 문서에서 1개의 문장만 추출하는 경우에는 MATCHSUM 모델은 문장을 재배열(re-rank)하는 모델로 퇴화합니다.
위 표는 위에서 설명한 것처럼 모델이 퇴화했더라도 다른 모델에 비해서는 조금 성능이 향상된 것을 확인할 수 있습니다.
게다가 MATCHSUM 모델은 다른 모델들이 추출할 요약문의 개수가 정해져있는 것과 달리 후보군 요약문 모두를 semantic space에 매칭시켰기때문에 원하는 추출 요약문 개수대로 추출할 수 있습니다.
Results on Datasets with Long Summaries
요약문의 길이가 길어질 경우, summary level matching은 점점 복잡해집니다.
본 논문에서는 Trigram Blocking 방법과 MATCHSUM모델에서 사용하는 방법을 비교해봅니다.


CNN/DM에서는 Trigram-Blocking은 상당히 좋은 결과를 보여주지만 위의 표를 통해서 모든 데이터셋에서 stable하게 성능 향상을 이뤄내지 않는다는 것을 알 수 있습니다.
Ngram-Blocking 은 wikihow, multi-news 데이터셋에서는 소폭 영향을 미치지만 PubMed 데이터셋에서는 크게 떨어지는 성능을 보여줍니다.
본 논문에서는 요인으로는 Ngram-Blocking은 문장과 요약문의 의미론적 이해가 이루어지지 않고 수많은 단어들의 개체의 존재를 한번으로 규제하기 때문입니다. - 명백하게 개체가 자주 여러번 존재하는 과학적 domain에서는 맞지 않습니다.
그에 반해 논문에서 제안하는 방법은 이러한 규제 없이 요약문을 포함한 원본 문서를 semantic space에 정렬합니다.
5.4 Analysis
본 논문의 분석은 2개의 질문에 답할 수 있습니다.
1) MATCHSUM 모델의 이점은 Section3에서 분석한 데이터셋의 속성과 일치하는지?
2) MATCHSUM 모델이 다양한 데이터셋에서 다른 성능을 보여줄까?
Dataset Splitting Testing
여기서는 실험에서 가장 좋은 성능을 보인 XSum, CNN/DM, WikiHow 데이터셋을 가지고 분석합니다.
먼저 Section3.2에서 사용하였던 z(best summary의 index값)의 분포도에 따라 3개의 데이터셋을 동일한 크기를 가지는 5개 파트로 나누고 하위 집합을 사용하여 진행합니다.

Figure4는 쉽게 설명하면 z(best summary의 rank index)를 5등분하여 집합한 것으로 X축이 z가 1분위 ~ 5분위로 증가하는 것을 표시하고 Y축은 MATCHSUM, BERTEXT를 비교하여 ROUGE score가 얼마나 향상되었는지를 표시합니다.
보면 MATCHSUM과 BERTEXT는 z=1(best summary가 pearl summary가 아닐때)이면 가장 작은 성능 차이를 보입니다. 이런 경우, 우리가 이해했던 바와 같이 summary level의 추출기의 pearl summary를 발견하기 위한 능력은 이점을 가져오지 않습니다.
z가 증가함에 따라, ROUGE score의 차이가 점점 커지는 걸 확인할 수 있고 CNN/DM 데이터셋에서는 특히나 pearl summary 개념과 유사하게 매치되고 있습니다.
WikiHow 데이터셋은 CNN/DM과 비슷하게 best summary가 가장 높은 점수를 받은 문장으로만 구성된 경우(z=2)에는 성능 차이는 다른 샘플보다 작습니다.
XSum 데이터셋에서는 다른 데이터셋과 조금 다르게 z가 Large인 경우에는 좋지않은 성능을 보여줍니다.
Comparison Across Datasets(데이터셋 간 비교)
MATCHSUM 프레임워크가 가져온 개선 사항이 Section3.3에 제시된 scoring 방식과 관련이 되어야 합니다.
이러한 관계를 이해하기 위해 아래의 식을 소개합니다.

*CMS = 문서(D)안에서 MATCHSUM으로 추출한 후보군요약
*CBE = 문서(D)안에서 BERTEXT으로 추출한 후보군요약
△(D)*는 데이터셋 D에서 MATCHSUM,BERTEXT 모델간의 향상성 관계를 파악합니다.
더욱이 sentence level과 summary level 추출기 간에 inherent gap(내재적 격차)을 비교하기 위해서 우리는 아래의 식(비율)을 MATCHSUM이 dataset(D)에서 학습할 수 있도록 추가로 정립합니다.
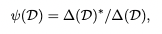
*∆(D)는 sentence level과 summary level 추출기 간에 inherent gap 입니다.

위 그래프를 통하여 ψ(D)는 z와 관련되어 있으며 중요요약(gold summary)의 길이와 관련이 있다는 것을 명백히 알 수 있습니다.
중요요약(gold summary)의 길이가 길어질수록 summary level에서의 접근 방식의 상한선에 MATCHSUM이 도달하기 어려워 집니다.
(XSum 데이터셋(23.3 word summary)에서는 ψ(D)= 0.64, PuhMed,Multi-News(200 word 초과)에는 ψ(D)= 0.2)
6. Conclusion
본 논문에서는 의미론적 텍스트 matching 문제를 해결하기 위해 semantic space에 원본문서와 후보군 요약을 매칭시키는 summary level에서의 프레임워크를 제안했습니다.
6개의 데이터셋에서 더 좋은 성능을 보였습니다.
'AI 일별 공부 정리' 카테고리의 다른 글
| MATCHSUM 구현하기 - 세부사항 확인 및 구현 (2) | 2022.12.13 |
|---|---|
| MATCHSUM 구현하기 - 논문 정리(2) (0) | 2022.11.01 |
| MATCHSUM 구현하기 - 논문 정리(1) (1) | 2022.10.31 |
| 시계열 데이터 예측에 대하여(Forecasting: Principles and Practice)-(3) (0) | 2022.01.04 |
| 시계열 데이터 예측에 대하여(Forecasting: Principles and Practice)-(2) (0) | 2021.12.30 |