
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 스타터스
- 취업부트캠프
- 유데미큐레이션
- sql정리
- NLP
- 그로스해킹
- 임베딩
- 특성중요도
- 사이드프로젝트
- 토스
- 스타터스부트캠프
- 데이터도서
- AWS builders
- MatchSum
- 딥러닝
- AARRR
- SQL
- pytorch
- 부트캠프후기
- SLASH22
- NLU
- 취업부트캠프 5기
- 알고리즘
- 추천시스템
- BERT
- 유데미코리아
- 유데미부트캠프
- 그래프
- 서비스기획
- 서비스기획부트캠프
- Today
- Total
다시 이음
실전 예측 분석 모델링 - 3 Feature Importances & Boosting 본문
Feature Importances & Boosting
안녕하세요.
오늘은 결정트리와 랜덤포레스트에 대해서 공부했을 때 빠지지 않고 등장했던 특성중요도(Feature importance)의 다른 방법들을 알아볼 예정입니다.
또한, 트리 앙상블 모델중에 하나인 Boosting ( Ada boost, Gradient boost ) 에 대해서도 알아보겠습니다.
Feature Importances
모델 기반 변수 선택(Model based method)
우리가 회귀모델에 대해서 배울때( 이전 포스트인 https://thogood212.tistory.com/21?category=993583 참조해주세요. ) SelectKBest 라는 메소드를 공부했습니다.
SelectKBest 메소드는 단일 변수 선택법 으로 특성 선택 ( Feature Selection ) 방법 중에 하나입니다.
그 중에 모델기반 변수 선택인 특성 중요도를 기반으로 특성을 선택하는 방법을 찾아보겠습니다.
모델 기반 변수 선택이란,
트리 기반 모델(또는 선형모델)들이 특성 중요도(Feature Importance)를 제공하는 것에 기반한 방법입니다.
특성 중요도는 예측의 불확실성을 낮출수록 증가하므로, (X,y)를 트리 기반 모델에 학습시킨 뒤, 특성 중요도가 기준치보다 높은 특성을 선택하는 방법입니다. 특성 선택에 사용한 모델과, 최종 예측 모델은 다를 수 있습니다.
1. Feature Importances(Mean decrease impurity, MDI)
sklearn 트리 기반 분류기에서 디폴트로 사용되는 특성 중요도 입니다. 속도는 빠르지만 주의해야합니다.
각각 특성을 모든 트리에 대해 평균불순도감소(mean decrease impurity)를 계산한 값.
( https://thogood212.tistory.com/24?category=993583 이 포스트에 평균불순도(Gini불순도에 대한 자세한 설명이 되어있습니다. )
# 특성 중요도
rf = pipe.named_steps['randomforestclassifier']
importances = pd.Series(rf.feature_importances_, X_train.columns)
%matplotlib inline
import matplotlib.pyplot as plt
n = 20
plt.figure(figsize=(10,n/2))
plt.title(f'Top {n} features')
importances.sort_values()[-n:].plot.barh();
궁금증 타임) high-cardinarity 특성이 MDI 방법으로 확인 시에 상대적으로 특성중요도가 높다고 나오는 이유?
제가 생각하기로는 지니불순도를 보면 분리되어진 자식노드의 데이터 크기 차이가 클수록 불순도가 낮기 때문에 정보획득량(Information Gain)이 커지게 될 것입니다. 배운대로 정보획득량이 높아야 상위 노드로 결정되고 상위노드일 수록 특성중요도가 크다고 볼 수 있겠죠.
이렇게 자식노드의 데이트 크기 차이가 크려면 high-cardinality와 같이 다양한 값을 가지되 그에 맞게 과적합되는 모델이라면 분리되는 데이터의 차이가 크게 되어 특성중요도가 높게 나오는 오류를 범할 수 있다고 생각합니다.
실험을 해보면 트리의 과적합 방지 정도에 따라 불순도를 기반으로 하는 변수 중요도는 큰 차이를 보입니다.
트리가 노드를 분리하는 것을 중간에 멈추지 않을 경우에는 연속형 변수일수록, cardinality가 클수록 노드 중요도가 매우 커진다는 것을 알 수 있습니다.
그래서, 불순도 기반 변수 중요도는 모델을 과적합 시키지 않는 선에서는 좋은 참고 자료가 될 수 있을 것이라 생각합니다.
각 parameter에 따라 변수 중요도가 어떻게 차이나는지까지 확인하게 되면, 이 나름의 정보를 얻게 되는 것 같습니다.
한계점들이 존재하긴 하지만, 트리에 특화된 이 불순도 기반 변수 중요도는 다른 방법을 따로 적용할 필요가 없고 빠르다는 점에서, 다른 방법을 통해 얻은 변수 중요도와 비교할 수 있는 좋은 대조군이라 생각합니다.
2. Drop-Column Importance
특성을 제거하기전에 평가지표를 통해 score을 확인하고 하나의 특성을 제거한 뒤 score를 확인하여 그 차이가 가장 큰 특성을 확인하는 방법입니다.
이 방법은 사람이 손으로 실행을 해야해서 가장 확실한 방법임에도 자주 사용되지 않습니다.
column = '열이름'
# 특성1개 없이 fit
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1)
)
pipe.fit(X_train.drop(columns=column), y_train)
score_without = pipe.score(X_val.drop(columns=column), y_val)
print(f'검증 정확도 ({column} 제외): {score_without}')
# 특성 포함 후 다시 학습
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1)
)
pipe.fit(X_train, y_train)
score_with = pipe.score(X_val, y_val)
print(f'검증 정확도 ({column} 포함): {score_with}')
# 특성 포함 전 후 정확도 차이를 계산합니다
print(f'{column}의 Drop-Column 중요도: {score_with - score_without}')
3. 순열중요도, (Permutation Importance, Mean Decrease Accuracy,MDA)
순열 중요도는 기본 특성 중요도와 Drop-column 중요도 중간에 위치하는 특징을 가진다고 볼 수 있습니다.
중요도 측정은 관심있는 특성에만 무작위로 노이즈를 주고 예측을 하였을 때 성능 평가지표(정확도, F1, 𝑅2 등)가 얼마나 감소하는지를 측정합니다.
Drop-column 중요도를 계산하기 위해 재학습을 해야 했다면, 순열중요도는 검증데이터에서 각 특성을 제거하지 않고 특성값에 무작위로 노이즈를 주어 기존 정보를 제거하여 특성이 기존에 하던 역할을 하지 못하게 하고 성능을 측정합니다.(즉, 재학습(Refit)이 필요하지 않습니다.)
이때 노이즈를 주는 가장 간단한 방법이 그 특성값들을 샘플들 내에서 섞는 것(shuffle, permutation) 입니다.
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
# encoder, imputer를 preprocessing으로 묶었습니다. 후에 eli5 permutation 계산에 사용합니다
pipe = Pipeline([
('preprocessing', make_pipeline(OrdinalEncoder(), SimpleImputer())),
('rf', RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1))
])
# pipeline 생성을 확인합니다.
pipe.named_steps
#검증 정확도 파악
pipe.fit(X_train, y_train)
print('검증 정확도: ', pipe.score(X_val, y_val))
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
#eli5 라이브러리 불러오기
import eli5
from eli5.sklearn import PermutationImportance
# permuter 정의
permuter = PermutationImportance(
pipe.named_steps['rf'], # model
scoring='accuracy', # metric
n_iter=5, # 다른 random seed를 사용하여 5번 반복
random_state=2
)
# permuter 계산은 preprocessing 된 X_val을 사용합니다.
X_val_transformed = pipe.named_steps['preprocessing'].transform(X_val)
# 실제로 fit 의미보다는 스코어를 다시 계산하는 작업입니다
permuter.fit(X_val_transformed, y_val);
# 특성중요도 나열해서 보기
feature_names = X_val.columns.tolist()
pd.Series(permuter.feature_importances_, feature_names).sort_values()
# 특성별 score 확인 시각화
eli5.show_weights(
permuter,
top=None, # top n 지정 가능, None 일 경우 모든 특성
feature_names=feature_names # list 형식으로 넣어야 합니다
)
순열중요도를 통해서 특성 선택하기
# 순열중요도의 최저값을 0.01로 설정하여 그 밑의 값들은 제거
minimum_importance = 0.001
mask = permuter.feature_importances_ > minimum_importance
features = X_train.columns[mask]
X_train_selected = X_train[features]
X_val_selected = X_val[features]
pipe.fit(X_train_selected, y_train);
# 순열 중요도의 평균 감소값과 그 표준편차의 차가 양수인 특징들을 확인할 수 있습니다.
permuter.feature_importances_ - permuter.feature_importances_std_ > 0
Boosting ( Ada boost, Gradient boost )
Boosting에 대해서 보기 전에 그 위의 분류인 트리 앙상블 모델에 대해서 먼저 확인해보겠습니다.
분류문제를 풀기 위해서는 트리 앙상블 모델을 많이 사용합니다.
- 트리 앙상블은 랜덤포레스트나 그래디언트 부스팅 모델을 이야기 하며 여러 문제에서 좋은 성능을 보이는 것을 확인하였습니다.
- 트리모델은 non-linear, non-monotonic 관계, 특성간 상호작용이 존재하는 데이터 학습에 적용하기 좋습니다.
- 한 트리를 깊게 학습시키면 과적합을 일으키기 쉽기 때문에. 배깅(Bagging, 랜덤포레스트)이나 부스팅(Boosting) 앙상블 모델을 사용해 과적합을 피합니다.
- 랜덤포레스트의 장점은 하이퍼파라미터에 상대적으로 덜 민감한 것인데, 그래디언트 부스팅의 경우 하이퍼파라미터 셋팅에 따라 랜덤포레스트 보다 더 좋은 예측 성능을 보여줄 수도 있습니다.(하이퍼 파라미터에 랜덤포레스트에 비해 민감합니다.)
Bagging과 Boosting 차이점
랜덤포레스트의 경우 각 트리를 독립적으로 만들지만 부스팅은 만들어지는 트리가 이전에 만들어진 트리에 영향을 받습니다.
1. Ada Boost

랜덤포레스트는 여러개의 가지를 가지는 n개의 트리들(병렬)로 이루어져 있지만 Ada boost는 한 특성으로 한번의 분리만 합니다.
그렇게 만들어진 것을 트리가 아닌 stump(나무그루터기)라고 합니다. 그리고 이러한 stump를 여러가지 두어 순서대로 처리합니다.
AdaBoost는 각 트리(약한 학습기들, weak learners)가 만들어질 때 잘못 분류되는 관측치에 가중치(Sample weight)를 줍니다.
그리고 다음 트리가 만들어질 때 이전에 잘못 분류된 관측치가 더 많이 샘플링되게 하여 그 관측치를 분류하는데 더 초점을 맞춥니다.
-알고리즘 과정
0. stump는 gini 계수를 계산해서 가장 낮은 특성부터 순차적으로 설정합니다.
1. 모든 관측치에 대해 가중치(Sample weight)를 동일하게 설정 합니다.
2. Total error라는 개념을 도입하는데 잘못 분류된 데이터의 가중치를 모두 더하면 Total error입니다.
3. Total error를 수치화 할 수 있는 Amount of Say를 사용합니다.
Amount of Say는 비선형형태를 띄며 Total error가 작을 수록 큰 값을 반환합니다.

4. 이 수치를 통해 아래의 식을 통해 잘못 분류된 데이터의 새로운 가중치를 생성합니다.

5. 옳게된 데이터의 새로운 가중치는 아래 처럼 구합니다.

6. 새로운 가중치를 모두 구했습니다. 이제는 총합이 1이 될 수 있도록 Normalize를 합니다.
7. 샘플링 방법
- 0~1사이의 숫자를 랜덤으로 추출한다.
- new sample weight가 0.07, 0.07, 0.49, 0.07 이렇게 되어있다고 가정해보겠습니다. 랜덤으로 뽑힌 수가 0.08 이면 2번째 데이터가 0.06이면 1번째 데이터가 뽑히게 된다. (new sample weight로 범주를 만든다고 생각하면 이해가 쉬워요.)
- 설명을 덧붙이면, 첫번째 데이터는 0~0.07사이의 값이 나오면 선택, 두번째 0.07~0.14, 세번째 0.14~0.63 의 수가 나오면 선택됩니다. 이렇게 하는 방식은 sample 가중치가 높을 경우 더 많이 선택되어 더 강조되게 만들어주겠죠?
8. 이 과정을 n회 반복(n = 3) 합니다.(이 과정을 통해 오류 데이터를 좀더 많이 학습하여 계속해서 개선하는 과정을 거칩니다.)
9. 분류기들(D1, D2, D3)을 결합하여 최종 예측을 수행합니다.
10. stump의 amount of say를 총합해서 가장 높은 값을 가진 boost가 좋은 boost입니다.
2. Gradient Boost
Gradient Boost는 하나의 Leaf node로 시작합니다.
이 값을 초기 예측 값이라고 하고 이 값을 바탕으로, 새로운 Tree 를 만들고, 또 그 값을 바탕으로 Tree 를 만드는 과정을 거칠 거에요.
-알고리즘 과정
0. 특성 데이터(타겟 포함)를 사용하여 예측값을 생성합니다. 예측값은 일반적으로 타겟열의 평균(A)으로 생성합니다.
1. 원본데이터의 타겟값과 평균 타겟값의 잔차(B)를 구하여 하나의 열을 생성합니다.
2. 우리는 이제 특성 데이터로 결정 트리를 만듭니다. 마지막노드에 각각의 잔차값(C)을 입력합니다. 마지막 노드에 2개 이상의 잔차값이 쌓였다면 그 사이의 평균을 냅니다.
3. 이제 맨처음 구했던 타겟열의 평균(A)에 0.1*노드 잔차값 (C)을 더합니다. 이 과정을 통해 실제 타겟값과의 차이가 줄어드는 것을 확인이 가능합니다.
4. 이렇게 나온 새로운 값(타겟열 평균 + 0.1*노드 잔차값)을 잔차값(B)으로 갱신해줍니다.
5. 이 잔차값을 통해 위의 과정을 계속해서 반복한다면 점점 잔차값이 줄어드는 것을 볼 수 있습니다.
즉, High Variance 를 피하면서, 조금씩 조금씩 학습해나가는 것입니다.
여기에, Gradient Boost 의 Gradient 의 의미가 바로 여기에 있습니다.
tip) 사용가능한 라이브러리
Python libraries for Gradient Boosting
scikit-learn Gradient Tree Boosting — 상대적으로 속도가 느릴 수 있습니다.
Anaconda: already installed
Google Colab: already installed
xgboost — 결측값을 수용하며, monotonic constraints를 강제할 수 있습니다.
Anaconda, Mac/Linux: conda install -c conda-forge xgboost
Windows: conda install -c anaconda py-xgboost
Google Colab: already installed
LightGBM — 결측값을 수용하며, monotonic constraints를 강제할 수 있습니다.
Anaconda: conda install -c conda-forge lightgbm
Google Colab: already installed
CatBoost — 결측값을 수용하며, categorical features를 전처리 없이 사용할 수 있습니다.
Anaconda: conda install -c conda-forge catboost
Google Colab: pip install catboost
# xgboost 라이브러리를 사용하여 Gradient boost쓰기
from xgboost import XGBClassifier
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy='median'),
XGBClassifier(n_estimators=200
, random_state=2
, n_jobs=-1
, max_depth=7
, learning_rate=0.2
)
)
pipe.fit(X_train, y_train);
Early Stopping
하이퍼 파라미터에 Early Stopping을 사용하여 과적합을 피합니다.
Early stopping 이란,
설명을 위해 이전에 한번 보았던 하이퍼파라미터 값 변화에 따른 검증곡선과 훈련곡선이 필요합니다.
훈련곡선과 검증곡선은 하락하는 모습을 보여줍니다.
그러가다 검증곡선(노란색)이 하락을 멈추는 때가 최적의 파라미터 값입니다.
그 이후로는 훈련데이터에 대해 과적합이 이루어지게 됩니다.
이렇게 검증곡선의 성능이 더이상 하락을 하지 않을 때에 Early stopping 파라미터를 설정하면 그 값에서 score 개선이 없다면 멈추게 됩니다.
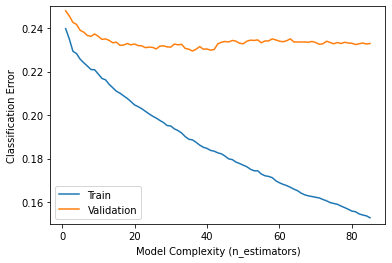
왜 n_estimators 최적화를 위해 GridSearchCV나 반복문 대신 early stopping을 사용할까요?
n_iterations 가 반복수라 할때, early stopping을 사용하면 우리는 n_iterations 만큼의 트리를 학습하면 됩니다.
하지만 GridSearchCV나 반복문을 사용하면 무려 sum(range(1,n_rounds+1)) 트리를 학습해야 합니다!
거기에 max_depth, learning_rate 등등 파라미터 값에 따라 더 돌려야 합니다.
encoder = OrdinalEncoder()
X_train_encoded = encoder.fit_transform(X_train) # 학습데이터
X_val_encoded = encoder.transform(X_val) # 검증데이터
model = XGBClassifier(
n_estimators=1000, # <= 1000 트리로 설정했지만, early stopping 에 따라 조절됩니다.
max_depth=7, # default=3, high cardinality 특성을 위해 기본보다 높여 보았습니다.
learning_rate=0.2,
# scale_pos_weight=ratio, # imbalance 데이터 일 경우 비율을 적용합니다.
n_jobs=-1
)
eval_set = [(X_train_encoded, y_train),
(X_val_encoded, y_val)]
model.fit(X_train_encoded, y_train,
eval_set=eval_set,
eval_metric='error', # #(wrong cases)/#(all cases)
early_stopping_rounds=50
) # 50 rounds 동안 스코어의 개선이 없으면 멈춤
하이퍼파라미터 튜닝
Random Forest
- max_depth (높은값에서 감소시키며 튜닝, 너무 깊어지면 과적합)
- n_estimators (적을경우 과소적합, 높을경우 긴 학습시간)
- min_samples_leaf (과적합일경우 높임)
- max_features (줄일 수록 다양한 트리생성, 높이면 같은 특성을 사용하는 트리가 많아져 다양성이 감소)
- class_weight (imbalanced 클래스인 경우 시도)
XGBoost
- learning_rate (높을경우 과적합 위험이 있습니다)
- max_depth (낮은값에서 증가시키며 튜닝, 너무 깊어지면 과적합위험, -1 설정시 제한 없이 분기, 특성이 많을 수록 깊게 설정)
- n_estimators (너무 크게 주면 긴 학습시간, early_stopping_rounds와 같이 사용)
- scale_pos_weight (imbalanced 문제인 경우 적용시도)
'AI 일별 공부 정리' 카테고리의 다른 글
| 실전 예측 분석 모델링 - 5 더 알아보기 (0) | 2021.09.08 |
|---|---|
| 실전 예측 분석 모델링 - 4 Interpreting Machine Learning Model (0) | 2021.08.27 |
| 실전 예측 분석 모델링 - 2 Data Wrangling (0) | 2021.08.25 |
| 실전 예측 분석 모델링 - 1 ML problems (0) | 2021.08.24 |
| EDA의 여러가지 방법 (0) | 2021.08.23 |



