
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- 그로스해킹
- 데이터도서
- 그래프
- 알고리즘
- 스타터스
- 사이드프로젝트
- 취업부트캠프 5기
- 임베딩
- AARRR
- sql정리
- NLP
- 부트캠프후기
- 취업부트캠프
- 딥러닝
- SQL
- 토스
- 유데미큐레이션
- MatchSum
- 유데미부트캠프
- NLU
- 추천시스템
- 서비스기획부트캠프
- 스타터스부트캠프
- 특성중요도
- SLASH22
- BERT
- 서비스기획
- pytorch
- AWS builders
- 유데미코리아
Archives
- Today
- Total
다시 이음
선형대수 - 2 (공분산과 상관계수) 본문
분산 ( Variance )
데이터가 얼마나 퍼져있는지를 측정하는 방법
- (각 값들과 평균과의 차이)의 제곱 평균.
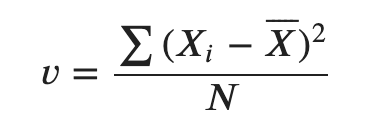
df.var(ddof=1) # 분산을 구하는 함수
# ddof = 0 : n으로 나눔 (모집단)
# ddof = 1 : n-1로 나눔 (표본집단)
표준편차 ( Standard Deviation )
분산 값에 루트를 씌운 값.
분산을 구하는 과정에서 평균에 비해 스케일이 커지는 문제가 있는데,표준 편차는 이를 해결 하기 위해서 제곱 된 스케일을 낮춘 방법
공분산 ( Covariance )
- 1개의 변수가 변화할 때 다른 변수가 어떠한 연관성을 나타내며 변하는지 측정하는 것.
- 즉, 2개의 확률변수의 선형 관계를 나타내는 값
상관관계의 상승(변수1이 증가할 때 변수2도 증가) 혹은 하강(변수1이 증가할때 변수2는 감소)하는 경향을 이해
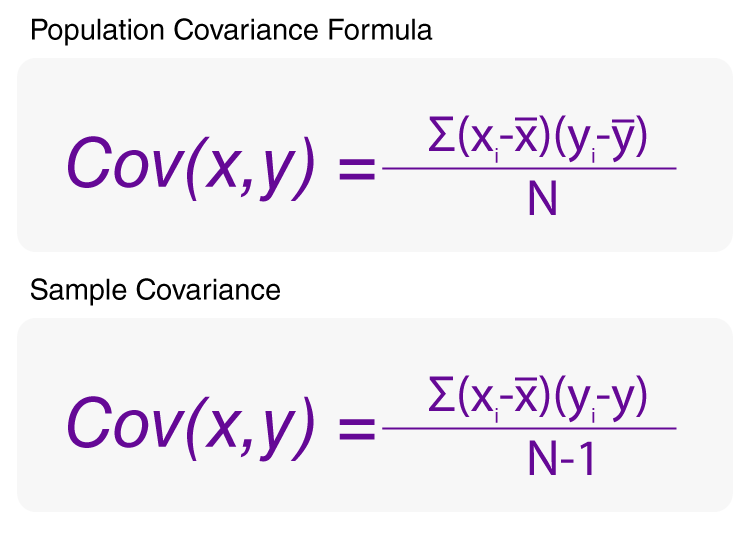
공분산 분석
- 아래의 코드블럭을 참고하여 파이썬에서 적용할 수 있다.
- \ 대각선방향은 자기자신변수에 대한 분산이다. 공분산을 확인하기 위해선 2x2일 때 np.cov()[0][1]로 설정해야 바로 공분산 데이터를 볼 수 있다.
- 이렇게 다른 변수와의 연관성을 파악할 수 있는 방법은? 카이제곱검정이 있었다.
import numpy as np
np.cov(x,y, ddof = 0)
def covariance(X, Y): # 공분산 함수만들기
ax, ay = X.mean(), Y.mean()
data = [round((ax-x)*(ay-y),2) for x, y in zip(X, Y)] # product of deriviations
return sum(data) / len(X)
분산공분산 행렬 (Variance-covariance matrix)
- 여러 개의 변수를 동시에 고려할 때, 각 변수의 분산과 변수 사이의 공분산을 요소로 구성된 행렬
- 대각선 행렬 값은 각 변수의 분산이고, 대각선 이외의 행렬 값들은 변수 사이의 공분산이다.
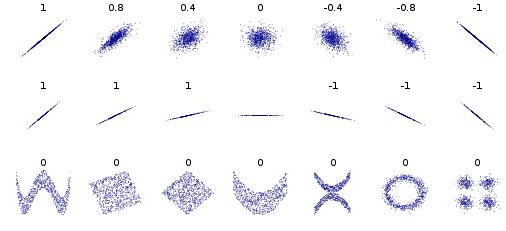
상관계수 ( Correlation coefficient ) - Pearson correlation
- 공분산을 두 변수의 표준편차로 각각 나눠주면 스케일을 조정
- 상관계수는 -1에서 1까지로 정해진 범위 안의 값만을 갖으며 선형연관성이 없는 경우 0에 근접
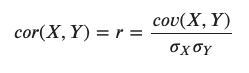
- 공분산의 값에 두 변수의 표준편차를 곱한 값을 나누면 상관계수를 얻을 수 있다.
np.corrcoef(x,y) # 함수
def correction(X,Y) :
a = np.cov(X,Y,ddof=0 or 1)
return a / (np.std(X)*np.std(Y)) # 내가 지정한 함수** 스피어먼 상관계수(spearman correlation coefficient)
- 스피어먼 상관계수는 두 변수 의 순위 사이의 통계적 의존성을 측정하는 비모수적인 척도
- 피어슨 상관계수와 같이 -1~1까지의 값을 가진다.
- 피어슨 상관계수가 numerical 데이터만 사용가능한 것을 보완하기 위해 categorical 데이터의 연관성을 파악하기 위해 적용.
벡터 직교 ( Orthogonality )
- 위의 상관계수를 통해 벡터간의 연관성뿐만 아니라 모든 벡터가 조금이라도 연관성을 가진다는 것이다.
- 물론 , 지금 설명하는 벡터 직교는 특정 벡터에 수직에 위치하는 벡터로 상관계수가 0이고 연관성이 없다.
- 또한 2개의 벡터를 내적하였을 때 그 값은 0이 된다.
단위 벡터 ( Unit Vectors )
- 단위 벡터란 "단위 길이(1)"를 갖는 모든 벡터
- v라는 벡터에 단위 벡터(u)를 찾으려면 아래 공식과 같이 사용하여야 한다.
- 단위 벡터의 의의는 v벡터와 같은 방향을 가진 벡터 u를 1의 길이로 만들어 정규화 한다는 것이다.
- 벡터를 단위벡터와의 조합으로 표현하기도 한다. 예 ) v = [5,20] = 5*i^ + 20*j^
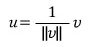
선형 결합( linear combination)
- 2개의 벡터를 스케일하고 더하여 새 벡터를 얻는 모든 연산
선형생성( linear span )
- 주어진 두 벡터의 (합이나 차와 같은) 조합으로 만들 수 있는 모든 가능한 벡터의 집합
- 벡터 2개가 선형관계가 같으면 하나의 직선이 생성.
- 벡터 2개가 선형관계가 같지 않다면 x,y축의 2차원 평면이 생성.
- 벡터 3개가 선형관계가 같지 않다면 x,y,z축의 3차원 공간이 생성.
선형 관계의 벡터 (Linearly Dependent Vector)
- 두 벡터가 같은 선상에 있는 경우, 이 벡터들은 선형 관계에 있다고 표현
선형 관계가 없는 벡터 (Linearly Independent Vectors)
- 같은 선상에 있지 않은 벡터들은 선형적으로 독립되어 있다고 표현
- 주어진 공간 (2개의 벡터의 경우 ℝ2 평면)의 모든 벡터를 조합을 통해 만들어 낼 수 있다.
기저 벡터 ( Basis vector )
- 벡터 공간 𝑉의 basis 는, 𝑉 라는 공간을 채울 수 있는 선형 관계에 있지 않은 벡터들의 모음
- 선형생성(span)에 부분집합으로 이해를 하면 좋다.
- Orthogonal Basis란, Basis 에 추가로 Orthogonal 한 조건이 붙는, 즉 주어진 공간을 채울 수 있는 서로 수직인 벡터
- Orthonomal Basis란, Orthogonal Basis에 추가로 Normalized 조건이 붙은 것으로, 길이가 서로 1인 벡터
Rank
- 매트릭스의 열을 이루고 있는 벡터들로 만들 수 있는 (span) 공간의 차원
- 매트릭스 차원과는 다를 수 있는데 그 이유는 선형관계에 있는 벡터의 유무 때문이다.
Gaussian Elimination(가우시안 소거법)
- 행 혹은 열벡터를 연산을 통해서 서로 같은 값을 만든다면 선형관계에 있다고 볼 수 있다.
- 단, 연립방정식의 형태를 띄는 경우에는 열벡터에는 가우시안 소거법이 적용이 되지 않는다.
예시 ) a = ([1,1,3],[0,1,2],[2,1,4)] -> 1번째 행벡터에 2를 곱하여 3번째 행벡터와 뺀다면 2번째 행벡터와 같은 값이 된다.
'AI 일별 공부 정리' 카테고리의 다른 글
| 선형 대수 - 4 ( Supervised Learning / Unsupervised Learning ) (0) | 2021.07.27 |
|---|---|
| 선형대수 -3 ( 고유벡터, PCA ) (0) | 2021.07.27 |
| 선형대수 -1 (벡터, 매트릭스) (0) | 2021.07.22 |
| 데이터 통계 - 4 (베이즈 정리) (0) | 2021.07.20 |
| 데이터 통계 - 3 (신뢰구간 설정과 ANOVA) (0) | 2021.07.19 |
'AI 일별 공부 정리' Related Articles
more



