
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 특성중요도
- 유데미부트캠프
- AARRR
- 딥러닝
- SQL
- 서비스기획부트캠프
- 취업부트캠프
- 데이터도서
- 임베딩
- 스타터스부트캠프
- 그래프
- 그로스해킹
- NLP
- 유데미큐레이션
- SLASH22
- 추천시스템
- 부트캠프후기
- 취업부트캠프 5기
- 사이드프로젝트
- MatchSum
- 서비스기획
- 스타터스
- BERT
- 토스
- pytorch
- AWS builders
- sql정리
- 알고리즘
- NLU
- 유데미코리아
- Today
- Total
다시 이음
선형 대수 - 4 ( Supervised Learning / Unsupervised Learning ) 본문
선형 대수 - 4 ( Supervised Learning / Unsupervised Learning )
Taeho(Damon) 2021. 7. 27. 23:42지도 학습 (Supervised Learning)
데이터에 라벨이 있을 때 사용 가능.
- 분류(Classification) : 주어진 데이터가 카테고리 혹은 클래스 예측을 위해 사용
- 회귀(Prediction) : 주어진 데이터가 continuous할 때 결과 예측을 위해 사용
비지도 학습 (Unsupervised Learning)
- 클러스터링 ( Clustering ) : 데이터와 연관된 feature을 바탕으로 유사한 그룹을 생성.
- 차원 축소 ( Dimentionality Reduction )
- 연관 규칙 학습 ( Association Rule Learning ) : feature들의 관계를 발견하는 방법
클러스터링 ( Clustering ) - 군집화
목적 : 주어진 데이터가 얼마나, 어떻게 유사한지 확인하기
데이터를 요약,정리할 때 매우 효율적인 방법으로 통한다.
종류 :
1 ) 계층적 클러스터링 ( Hierarchical )
- Agglomerative : 개별 포인트에서 시작하여 점점 크게 합쳐가는 형태
- Divisive : 한 개의 큰 군집에서 점점 작은 군집으로 나누는 형태
2) Point Assignment
- 처음에 군집의 수를 정하고 데이터를 군집에 하나하나 배정하는 형태
3) Hard Clustering
- 데이터는 하나의 군집에만 할당된다.
4) Soft Clustering
- 데이터는 여러 군집에 확률을 가지고 할당된다.
유사성 ( Similarity )
클러스터링은 어떻게 유사성을 파악하여 클러스터를 배정할까?
- 유클리디안 ( Euclidean )
두 변수의 거리를 측정하여 유사도를 파악하는 방법.
a = np.array((1, 2, 3))
b = np.array((4, 5, 6))
dist = np.linalg.norm(a-b)
# 벡터의 길이를 측정하는 방법으로 확인 가능그 외의 방법들 : Cosine, Jaccard, Edit Distance ( 궁금하다면 추가적으로 찾아서 공부하기 )
K-Means Clustering
A.K.A. centroid-based clustering
(K는 중심점의 개수)
유사성은 K-Means 클러스터링 메커니즘에 크게 중요하다.
데이터와 클러스터의 거리(유클리드)의 제곱한 총합(오차제곱합)을 최소화 함으로써 최적의 클러스터 배치를 결정한다.
이러한 메커니즘을 사용하여 최적의 클러스터 수를 확인하는 것이 Elbow methods이다.

진행 과정
1) k 개의 랜덤한 데이터를 cluster의 중심점으로 설정
2) 해당 cluster에 근접해있는 데이터를 cluster로 할당
3) 변경된 cluster에 대해서 중심점을 새로 계산
# 중심점 계산하기
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
x, y = make_blobs(n_samples = 100, centers = 3, n_features = 2)
# 데이터셋을 만드는 데 100개의 샘플을 3개의 중심점을 가지게 2개의 feature를 기준으로 만든다.
plt.scatter(points.x, points.y)
plt.show()
# 산포도를 통해 만들어진 데이터셋이 어떻게 분포되어 있는지 파악해보기
centroids = points.sample(3) # 랜덤으로 중심점 3개 만들어보기
from scipy.spatial import distance
def find_nearest_centroid(df, centroids, iteration반복):
# 포인트와 centroid 간의 거리 계산
distances = distance.cdist(df, centroids, 'euclidean')
# 제일 근접한 centroid 선택
nearest_centroids = np.argmin(distances, axis = 1)
# cluster 할당
se = pd.Series(nearest_centroids)
df['cluster_' + iteration] = se.values
반복하여 유의미한 변화가 없을 때 중심점이라고 본다.K-means에서 K를 결정하는 방법
Elbow methods
클러스터 개수를 1이라고 할 때 오차제곱합을 측정하고 그 값을 저장, 또 2,3,4... 계속해서 측정과 저장을 하여 최종적으로 그래프로 시각화 할 수 있다. 이러한 방법 때문에 그래프를 보았을 때 데이터와 클러스터간의 거리를 의미하는 오차제곱합의 수치가 점차 줄어들어 그 수치가 변화하는 구간이 미세할 때, 더이상 클러스터를 늘림으로써 데이터와 클러스터간의 거리가 줄어들지 않는다고 판단할 수 있다.
sum_of_squared_distances = []
K = range(1, 15)
for k in K:
km = KMeans(n_clusters = k)
km = km.fit(points)
sum_of_squared_distances.append(km.inertia_)
# 1~15개의 클러스터를 지정했을 때 각각 중심점간의 거리를 기록
plt.plot(K, sum_of_squared_distances, 'bx-')
plt.xlabel('k')
plt.ylabel('Sum_of_squared_distances')
plt.title('Elbow Method For Optimal k')
plt.show()
# 그래프를 통하여 Scree Plot과 같이 유의미한 변화를 보이지 않는 경우 전까지 중심점을 활용하면 된다.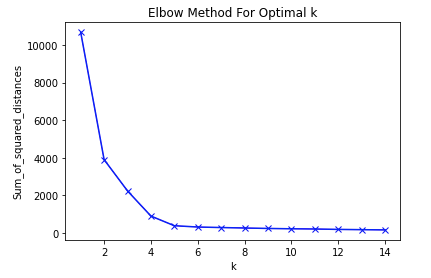
K-Means Clustering을 라이브러리를 사용해서 구하기
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3) # n_clusters = 구하고자 하는 클러스터의 개수입력
kmeans.fit(x)
labels = kmeans.labels_ # 구해진 k-means 클러스터열을 반환
new_series = pd.Series(labels)
df['clusters'] = new_series.values # 클러스터열('label')의 값들을 df열에 입력
# 위의 series를 그대로 넣으려고 하면 오류가 생기니 꼭 값으로 변환한 뒤에 넣기K-Means Clustering 시각화하기
산포도를 표현하며 클러스터 분류(라벨)을 통해 컬러가 자동 입력된다.
import matplotlib.pyplot as plt
plt.scatter(df['x열'],df['y열'],c=df['clusters(열)'],alpha=0.5)
K-Means Clustering을 사용할 때 주의점
1) 여러 feature들이 사용된 데이터셋일 경우에 각 feature들의 크기가 너무 크다면 StandardScaler().fit_transform(x)을 통해 표준화를 진행하면 결과값을 분석하기 쉽다.
2) 데이터셋에 수치형이지만 해당 데이터의 정보에 불필요한 값은 제외시키는 전처리 과정을 꼭 거친 뒤 진행하여야 유의미한 결과를 얻을 수 있다.
3) 데이터셋에 분류된 값(라벨)이 없다면 해당 과정을 거쳐도 정말 이 값이 정확하다고 파악하기는 어렵다.
4) feature가 엄청 많은 경우 PCA 전처리 과정을 거친 뒤 해당 과정을 진행하면 좀더 효율적일 것 같지만 그것에 대해서는 그럴 수도 있고 아닐 수도 있다.
5) feature가 많은 경우 해당 과정의 시각화(산포도)를 해보고 싶다면 PCA를 활용하여 차원축소하여 시각화를 하는 것이 좋다.
'AI 일별 공부 정리' 카테고리의 다른 글
| 데이터를 적절하게 시각화 해보자 -2 ( feat. python) - 순위, 계층구조 (0) | 2021.08.06 |
|---|---|
| 데이터를 적절하게 시각화 해보자 -1 ( feat. python) - 분포, 상관관계 (0) | 2021.08.05 |
| 선형대수 -3 ( 고유벡터, PCA ) (0) | 2021.07.27 |
| 선형대수 - 2 (공분산과 상관계수) (0) | 2021.07.23 |
| 선형대수 -1 (벡터, 매트릭스) (0) | 2021.07.22 |



