
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 유데미부트캠프
- 유데미코리아
- BERT
- 스타터스부트캠프
- 특성중요도
- 취업부트캠프
- sql정리
- SLASH22
- 딥러닝
- 유데미큐레이션
- AWS builders
- NLP
- 취업부트캠프 5기
- 서비스기획
- pytorch
- SQL
- 서비스기획부트캠프
- 그로스해킹
- 추천시스템
- 알고리즘
- 부트캠프후기
- 데이터도서
- NLU
- 그래프
- 임베딩
- 스타터스
- MatchSum
- 토스
- AARRR
- 사이드프로젝트
- Today
- Total
다시 이음
회귀 분석 - 1 (단순선형회귀모델) 본문
선형회귀(Linear Regression)
지도 학습 (Supervised Learning) / 비지도 학습(Unsupervised Learning)
둘의 가장 큰 차이는 'Label (답)이 주어지는가, 아닌가' 이다.
즉, 지도학습이란 데이터와 라벨(레이블)을 입력하고 학습을 통해 데이터간의 룰을 찾아 분석하는 것이다.
비지도학습은 라벨이 주어지지 않은 데이터일 경우 군집화(클러스터링)을 통해 분리하는 것이다.
(비지도 학습은 답이 주어지지 않아서 분리를 한뒤에도 정확한 값이 맞는지 틀렸는지 확인이 어렵다.)
비지도 학습의 경우 클러스터링을 저번 포스팅에서 확인해본 바 있고
오늘은 지도 학습에 집중을 할 것이다.
1. 지도학습(Supervised Learning)은?
1) 회귀(Regression) & 분류(Classification)
| 회귀(Regression) | 분류(Classification) | |
| Output | 연속적 | 이산적, 클래스 레이블 |
| 목표 | 최적선(데이터의 선) | 결정 바운더리에 따라 레이블을 할당 |
| 평가방법 | 1. 제곱 오차의 합(RSS) 2. r제곱 | 정확도(accuracy) |
| 알고리즘 | 회귀 트리 (랜덤 포레스트), 선형 회귀 등 | 의사 결정 트리, 로지스틱 회귀 등 |
2) 기준모델(Baseline Model)
예측 모델을 구체적으로 만들기 전에 가장 간단하면서도 직관적이면서 최소한의 성능을 나타내는 기준이 되는 모델을 기준모델 이라고 합니다. 문제별로 기준모델은 보통 다음과 같이 설정합니다.
- 분류문제: 타겟의 최빈 클래스
- 회귀문제: 타겟의 평균값 (predict)
- 시계열회귀문제: 이전 타임스탬프의 값
Mean Absolute Error(MAE, 평균절대오차) 는 예측 error 의 절대값 평균이다.
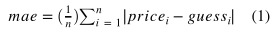
predict = df['열이름'].mean()
errors = predict - df['열이름']
mean_absolute_error = errors.abs().mean()
3) 효율적으로 선형회귀모델의 독립변수와 종속변수 설정하기
회귀 문제에서 기준모델을 설정하기 전에 데이터간의 상관관계를 파악하여 최대한 관련있는 독립변수와 종속변수로 회귀모델을 설정하는 것이 가장 효율적이다.
1. 상관계수(correlation coefficient)을 통해 종속변수에 가장 선형관계에 있는 독립변수 파악하기
- 상관계수는 이전에 포스팅에서 언급한 적이 있음으로 참고해주세요.
- 그래도 간단히 파악해보자면 -1에서 양수1까지의 범위의 수로 변수들의 상관관계를 표현.
- 1에 가까울 수록 양의 선형관계, -1에 가까울 수록 음의 선형관계 그리고 0에 가까울 수록 선형 연관성이 없다고 본다.
2. 시각화를 통한 데이터간의 상관관계 파악하기
sns.pairplot(비교하고자하는 데이터프레임, height=2)
pairplot은 대각선으로는 각각 변수에 대한 분포를 히스토그램으로 표현해주고 있으며 그외에는 다른 변수와의 관계를 산포도를 통해서 표현해준다.
산포도를 통해 변수끼리 어떠한 상관관계를 가지는지를 시각화하여 살펴볼 수 있다.
4) 예측모델(Predictive Model)
scatterplot에 가장 잘 맞는(best fit) 직선을 그려주면 그것이 회귀 예측모델
- 회귀직선?!
Linear Regression 이란 독립변수 x가 종속변수 y에 미치는 영향을 회귀식을 통해서 풀어놓은 것이다.
그렇게 만들어진 회귀식(방정식)은 선의 형태(회귀직선)로 나타나고 그 선이 주어진 x,y의 무수한 점들과의 거리(잔차)의 총합이 RSS(residual sum of squares)이다.
RSS를 구하는 방법은 Linear Projections(투영)을 통해 점과 선의 거리를 구하는 원리를 통해 도출 할 수 있다.
OLS (Ordinary least squares) : 최소제곱법은 계산한 RSS을 최소한으로 만드는 것으로 단순선형회귀모델을 만들어 낼 수 있다.

- 선형회귀계수 구하기
최소제곱법(OLS)를 통해 선형회귀계수를 계산.
- 선형 회귀계수는 무엇일까??
y = ax + b 라는 회귀식을 통해 보면 x는 독립변수(independent variable), y는 종속변수(dependent variable), a가 선형회귀계수(Coefficients), b는 y절편(intercept)이라고 표현한다.
즉, 선형회귀계수란 방정식의 기울기이며, 독립변수의 변화가 얼마나 종속변수에 영향을 끼치는가를 표현하는 것이다.
#seaborn으로 회귀계수 시각화 해보기
sns.regplot(x=df['독립변수 열'], y=df['종속변수 열'])
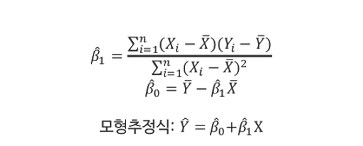
- β0 : 직선식의 절편(y절편)
- β1 : 직선식의 기울기(선형회귀계수)
- X,Y는 예측치 , X^,Y^은 평균값
5) 단순선형회귀모델 (Simple Linear Regression)
위의 선형회귀계수와 y절편을 구함으로써 우리는 단순선형회귀모델의 회귀식을 완성할 수 있습니다.
단순선형회귀모델을 통해서 우리는 무엇을 할 수 있을까요?
- 주어져 있지 않은 점의 함수값을 보간(interpolate) 하여 예측
- 기존 데이터의 범위를 넘어서는 값을 예측하기 위한 외삽(extrapolate)
- 독립변수와 종속변수의 관계확인
참조 )
종속변수는 반응(Response)변수, 레이블(Label), 타겟(Target) 등
독립변수는 예측(Predictor)변수, 설명(Explanatory), 특성(feature) 등으로 불리움.
- scikit-learn을 사용하여 단순선형회귀모델 구하기
- 특성행렬은 주로 X 로 표현하고 보통 2-차원 행렬입니다([n_samples, n_features]). 주로 NumPy 행령이나 Pandas 데이터프레임으로 표현합니다.
- 타겟배열은 주로 y로 표현하고 보통 1차원 형태(n_samples) 입니다. 주로 Numpy 배열이나 Pandas Series로 표현합니다.

## Scikit-Learn 라이브러리에서 사용할 예측모델 클래스를 Import 합니다
from sklearn.linear_model import LinearRegression
## 예측모델 인스턴스를 만듭니다
model = LinearRegression()
## X 특성들의 테이블과, y 타겟 벡터를 만듭니다
feature = ['독립변수 열']
target = ['종속변수 열']
X_train = df[feature] # X는 2차원이상 (데이터프레임)
y_train = df[target] # y는 1차원(데이터 프레임, 시리즈, array), 주로 시리즈,array를 자주 쓰나
# 라이브러리에 따라서 데이터프레임도 사용.(수학적으로 1차원인 것이 중요하다)
## 모델을 학습(fit)합니다
model.fit(X_train, y_train)
## 새로운 데이터 한 샘플을 선택해 학습한 모델을 통해 예측해 봅니다
X_test = [[4000]]
y_pred = model.predict(X_test)
## 전체 테스트 데이터를 모델을 통해 예측해 봅니다.
X_test = [[x] for x in df_t['GrLivArea']]
y_pred = model.predict(X_test)
## train 데이터에 대한 그래프를 그려보겠습니다.
plt.scatter(X_train, y_train, color='black', linewidth=1)
## test 데이터에 대한 예측을 파란색 점으로 나타내 보겠습니다.
plt.scatter(X_test, y_pred, color='blue', linewidth=1);
## 계수(coefficient)
model.coef_
## 절편(intercept)
model.intercept_
# sqft값에 따라 자동으로 예측해주는 함수 만들기
def explain_prediction(sqft):
y_pred = model.predict([[sqft]])
pred = f"{int(sqft)} sqft 주택 가격 예측: ${int(y_pred[0])} (1 sqft당 추가금: ${int(model.coef_[0])})"
return pred
## ipywidgets 라이브러리 통해서 시각화하기
from ipywidgets import interact
# 데코레이터 interact를 추가합니다.
@interact
def explain_prediction(sqft=(500,10000)):
y_pred = model.predict([[sqft]])
pred = f"{int(sqft)} sqft 주택 가격 예측: ${int(y_pred[0])} (1 sqft당 추가금: ${int(model.coef_[0])})"
return pred'AI 일별 공부 정리' 카테고리의 다른 글
| 회귀 분석 - 3 (Ridge Regression) (0) | 2021.08.12 |
|---|---|
| 회귀 분석 - 2 (다중회귀분석) (0) | 2021.08.10 |
| 데이터를 적절하게 시각화 해보자 -2 ( feat. python) - 순위, 계층구조 (0) | 2021.08.06 |
| 데이터를 적절하게 시각화 해보자 -1 ( feat. python) - 분포, 상관관계 (0) | 2021.08.05 |
| 선형 대수 - 4 ( Supervised Learning / Unsupervised Learning ) (0) | 2021.07.27 |



