
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- AARRR
- 취업부트캠프
- 취업부트캠프 5기
- 토스
- 스타터스부트캠프
- pytorch
- 추천시스템
- NLP
- 알고리즘
- SLASH22
- SQL
- sql정리
- NLU
- 유데미코리아
- BERT
- 데이터도서
- 유데미부트캠프
- AWS builders
- 부트캠프후기
- MatchSum
- 서비스기획부트캠프
- 서비스기획
- 유데미큐레이션
- 특성중요도
- 그로스해킹
- 임베딩
- 사이드프로젝트
- 그래프
- 스타터스
- 딥러닝
- Today
- Total
다시 이음
회귀 분석 - 3 (Ridge Regression) 본문
Ridge Regression
이전 포스팅에서 다루었던 연속형 데이터를 다루는 선형회귀분석이 있었습니다.
그렇다면 범주형 데이터(Categorical)는 어떻게 회귀분석 할 수 있을까요?
범주형 데이터(Categorical)
범주형 데이터는 순서가 없는 명목형(nominal)과 순서가 있는 순서형(ordinal)으로 나뉩니다.
이러한 범주형 데이터를 시스템이 인식할 수 있도록 변환시키는 방법중에 하나인 Onehotencoder에 대해서 살펴볼게요.
원핫인코딩을 수행하면 각 카테고리에 해당하는 변수들이 모두 차원에 더해지게 됩니다.
즉, 새로운 차원(열)에 0,1로 마킹을 한다고 생각하시면 됩니다.
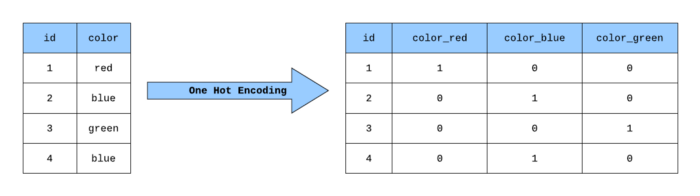
그러나 카테고리가 너무 많은 경우를 우리는 집단의 크기가 많다.(high Cardinality) 로 표현합니다.
cardinality는 편하게 카테고리의 요소의 개수라고 생각해도 좋습니다.
이 cardinality가 많은 경우에는 원핫인코딩을 사용하기엔 적합하지 않습니다. - 너무 차원이 방대해지기 때문입니다.
원핫인코딩 실행해보기
1) pandas get_dummies
df = pd.get_dummies(df, prefix=['카테고리형 열이름'])
2) category_encoders 라이브러리
from category_encoders import OneHotEncoder
from sklearn.model_selection import train_test_split
features = ['City','Room']
target = 'Price'
X = df[features]
y = df[target]
#메소드 사용하여 훈련데이터, 테스트데이터 나누기 (훈련 80%, 테스트 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.8, test_size=0.20, random_state=2)
#해당 라이브러리를 사용하면 카테고리형 데이터만 인코딩해준다.
encoder = OneHotEncoder(use_cat_names = True)
X_train = encoder.fit_transform(X_train)
X_test = encoder.transform(X_test)
특성 선택(Feature selection)
이전 포스트에 선형회귀분석을 할 때 종속변수(target)에 가장 상관관계가 있는 독립변수(Feature)을 설정하기 위해서 상관계수를 파악했습니다.
하지만 그것은 특성의 개수가 몇개 되지 않았기 때문에 시각화하거나 데이터화하여 눈으로 판별할 수 있었지만 특성이 더 많아진다면 어떨까요?
그래서 우리는 sklearn의 SelectKBest를 사용해 가장 효과적인 특성 K개를 골라보겠습니다.
## f_regresison, SelectKBest
from sklearn.feature_selection import f_regression, SelectKBest
## selctor 정의합니다.
selector = SelectKBest(score_func=f_regression, k=10 # k=선택할 특성개수
## 학습데이터에 fit_transform
X_train_selected = selector.fit_transform(X_train, y_train)
## 테스트 데이터는 transform
X_test_selected = selector.transform(X_test)
# 선택된 특성 크기보기 ( 10개의 열로 이루어짐 )
X_train_selected.shape, X_test_selected.shape
# 선택된 특성 알아보기
all_names = X_train.columns
## selector.get_support() - 불린 값으로 반환시켜주는 메소드
selected_mask = selector.get_support()
#선택된 특성들의 score을 보여준다.
selector.scores_[selected_mask]
## 선택된 특성들
selected_names = all_names[selected_mask]
## 선택되지 않은 특성들
unselected_names = all_names[~selected_mask]
print('Selected names: ', selected_names)
print('Unselected names: ', unselected_names)
그렇다면 가장 효율적인 k의 개수는 어떻게 알 수 있을까요?
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, r2_score
training = []
testing = []
ks = range(1, len(X_train.columns)+1)
# 1 부터 특성 수 만큼 사용한 모델을 만들어서 MAE 값을 비교 합니다.
for k in range(1, len(X_train.columns)+ 1):
print(f'{k} features')
selector = SelectKBest(score_func=f_regression, k=k)
X_train_selected = selector.fit_transform(X_train, y_train)
X_test_selected = selector.transform(X_test)
all_names = X_train.columns
selected_mask = selector.get_support()
selected_names = all_names[selected_mask]
print('Selected names: ', selected_names)
model = LinearRegression()
model.fit(X_train_selected, y_train)
y_pred = model.predict(X_train_selected)
mae = mean_absolute_error(y_train, y_pred)
training.append(mae)
y_pred = model.predict(X_test_selected)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
testing.append(mae)
print(f'Test MAE: ${mae:,.0f}')
print(f'Test R2: {r2} \n')
위의 코드를 통해서 MAE의 하락이 가장 변동이 큰 구간을 확인하고 그 지점의 k의 개수를 선정해서 사용하는 것이 좋습니다.
Ridge Regression(Ridge 회귀)
Ridge 회귀란 기존 다중회귀선을 훈련데이터에 덜 적합이 되도록 만든다는 것입니다.
Ridge 회귀를 사용하는 이유는
1)Ridge 회귀는 과적합을 줄이기 위해서 사용하는 것입니다.
2)과적합을 줄이는 간단한 방법 중 한 가지는 모델의 복잡도를 줄이는 방법입니다.
3)특성의 갯수를 줄이거나 모델을 단순한 모양으로 적합하는 것입니다.
4)그로인해 일반화 성능을 높여주어 Bais(편향)을 높여주고, Variance(분산)을 낮춰줍니다.
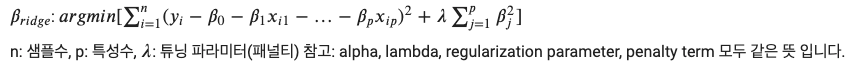
위의 공식을 보면 잔차제곱합 + (람다(페널티)값 * 기울기 제곱합) 을 함으로써 Ridge 회귀의 오류값을 형성합니다.
정리하자면 원래의 다중회귀모델과 새로 설정한 Ridge 회귀모델의 오류값을 비교할 때 위의 공식을 사용하며, 해당 값이 작을 수록 회귀분석이 탁월하다고 볼 수 있습니다.
lambda(페널티값, alpha)
람다의 값이 커질 수록, 학습 횟수를 줄인다는 뜻으로 회귀계수(기울기)의 값을 0에 수렴하게 됩니다.
람다의 값이 작아질 수록, 학습 횟수를 늘린다는 뜻으로 회귀계수(기울기)의 값이 다중회귀모델(OLS)와 같아집니다.
페널티를 적용함으로써 우리는 이상치(outlier) 때문에 전체적인 오류값이 높아지는 것을 방지 할 수 있습니다.
그렇다면 이 페널티(람다)의 값을 보다 효율적으로 구할 수 있는 방법을 알아봅시다.
여러 패널티 값을 가지고 검증실험을 해 보는 방법을 사용합니다.
교차검증(Cross-validation)을 사용해 훈련/검증 데이터를 나누어 검증실험을 진행하면 됩니다.
RidgeCV를 통한 최적 패널티(alpha, lambda) 검증
from sklearn.linear_model import RidgeCV
#임의의 페널티 값 설정
alphas = [0.01, 0.05, 0.1, 0.2, 1.0, 10.0, 100.0]
ridge = RidgeCV(alphas=alphas, normalize=True, cv=3) #cv= 교차검정 횟수
X_total = pd.concat([X_train, X_test])
y_total = pd.concat([y_train, y_test])
ridge = RidgeCV(alphas=alphas, normalize=True, cv=5)
ridge.fit(X_total, y_total)
print("alpha: ", ridge.alpha_)
print("best score: ", ridge.best_score_)
print("alpha: ", ridge.alpha_)
print("best score: ", ridge.best_score_)
위의 코드를 통해서 최적의 페널티값과 스코어점수 까지 확인이 가능합니다.
** 여기서 X_train,X_test로 나뉘어져 있던 훈련,테스트 데이터를 합쳐주는 것은 교차검정을 진행할 때 최대한 많은 데이터를 사용하여 효율성을 높이려는 목적으로 합쳐진 X_total의 데이터에서 cv 개수 만큼의 훈련, vaildation(검증) 데이터로 나뉘어 교차검증을 자동 실행하게 됩니다.
Ridge 회귀 학습
from sklearn.linear_model import Ridge
from sklearn.metrics import r2_score
# 아래와 같이 alpha 값을 임의로 지정도 가능하고 랜덤 코드를 사용할 수도 있습니다.
# 혹은 위에서 최적의 람다값을 확인하고 해당 값만 이용하여 학습시킬 수도 있습니다.
for alpha in [0.001, 0.005, 0.01, 0.02, 0.03, 0.1, 1.0, 1, 100.0, 1000.0]:
print(f'Ridge Regression, alpha={alpha}')
# Ridge 모델 학습
model = Ridge(alpha=alpha, normalize=True)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# MAE for test
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Test MAE: ${mae:,.0f}')
print(f'Test R2: {r2:,.3f}')
# plot coefficients #페널티가 커질수록 계수들이 작아지는 게 확인 가능
coefficients = pd.Series(model.coef_, X_train.columns)
plt.figure(figsize=(10,3))
coefficients.sort_values().plot.barh()
plt.show()
의문점 ( 추후 답을 얻게 되면 업데이트 예정 )
1) 특성 선택에서 k의 개수가 많을 수록 MAE가 낮아지고, R2는 1에 가까워지는데 강의노트에 나온 그래프에서 보이듯이 MAE값이 확 떨어지는 구간에서 k의 개수를 선택하는 게 가장 효율적이다 라고 이해하는 게 맞나요?
2) 특성들이 많이 사용되면 다항함수로 그에 따른 Ridge회귀분석은 pipe line을 활용하여 진행되는데 이 방식이 아닌 그냥 ridge 학습을 통해서도 정확한 값이 나오는 이유는 무엇일까?
'AI 일별 공부 정리' 카테고리의 다른 글
| 회귀 분석 - 5 (Polynomial Regression) (0) | 2021.08.16 |
|---|---|
| 회귀 분석 - 4 (Logistic Regression) (0) | 2021.08.13 |
| 회귀 분석 - 2 (다중회귀분석) (0) | 2021.08.10 |
| 회귀 분석 - 1 (단순선형회귀모델) (0) | 2021.08.09 |
| 데이터를 적절하게 시각화 해보자 -2 ( feat. python) - 순위, 계층구조 (0) | 2021.08.06 |



