
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 유데미큐레이션
- 부트캠프후기
- 토스
- NLU
- 추천시스템
- AWS builders
- SLASH22
- MatchSum
- 유데미코리아
- AARRR
- 데이터도서
- 서비스기획부트캠프
- 알고리즘
- 그로스해킹
- SQL
- pytorch
- BERT
- 취업부트캠프
- NLP
- 스타터스부트캠프
- 특성중요도
- 취업부트캠프 5기
- 스타터스
- 임베딩
- 딥러닝
- 사이드프로젝트
- 유데미부트캠프
- 그래프
- sql정리
- 서비스기획
- Today
- Total
다시 이음
회귀 분석 - 2 (다중회귀분석) 본문
Multiple Regression (다중회귀분석)
다중회귀 분석에 대한 설명을 하기전에 회귀분석을 위해 모델 설정을 하려면 우리가 해야할 것이 있습니다.
바로 독립변수(Feature) 와 종속변수(Target)의 데이터에서 훈련 데이터와 테스트 데이터를 분리하는 것입니다.
훈련(train)과 테스트(test)
테스트 데이터와 훈련데이터를 서로 분리하는 절차 = out of sample testing
훈련 데이터를 이용하여 모델을 만들고 테스트 데이터를 넣어서 모델의 효율을 확인하는 것에 의의가 있습니다.
훈련 데이터와 테스트 데이터를 나누는 방법은 무작위로 선택해 나누는 방법이 일반적입니다.
(시계열 데이터를 가지고 과거에서 미래를 예측하려고 하는 경우 무작위로 데이터를 섞으면 절대로 안됩니다. 이럴 경우엔 훈련 데이터가 테스트 데이터보다 과거에 있어야겠죠? )
# 데이터 나누기 예시
## 데이터의 75% 갯수
len(df)*0.75
## train/test 데이터를 sample 메소드를 사용해 나누겠습니다.
train = df.sample(frac=0.75,random_state=1)
test = df.drop(train.index)
#혹은 이렇게 sklearn 라이브러리를 통해 나눌 수도 있다.
from sklearn.model_selection import train_test_split
## X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = train_test_split(열이름, 열이름, random_state=1)
아웃라이어 제거하기
# target 설정 및 범주 확인
import seaborn as sns
target="열이름"
sns.displot(df_selected[target])
# outlier : 상위 5%로 설정
price_top_5percent = df_selected[target].quantile(q=0.95)
# outlier 제거
df_selected = df_selected[df_selected[target] < price_top_5percent]
# 시각화로 살펴보기
sns.displot(df_selected[target])
상관계수를 통해 feature 선택하기
# 모든 컬럼들을 산점도로 통해 시각화하여 살펴보기
import seaborn as sns
import matplotlib.pyplot as plt
from pandas.plotting import scatter_matrix
scatter_matrix(df, alpha=0.5, figsize=(20, 20), diagonal='kde')
plt.show()
# 상관계수 파악 & 시각화로 살펴보기
# 상관계수 구하기
df_selected_corr = df_selected.corr()
# 상관계수 히트맵 확인
plt.figure(figsize=(16, 12))
sns.heatmap(df_selected_corr, annot=True, cmap="YlOrRd");
#상관계수 : 순서대로 나열 후 상관계수 수치를 확인하여 feature 선택 여부 결정
df_target_corr = df_selected_corr[['target열이름']].sort_values('target열이름', ascending=False)
# BEST 5 특성 불러오기
df_target_corr[1:6]
다중선형회귀모델 생성하기
단순선형회귀모델을 생성하는 것과 같으며 다른 점은 독립변수(Feature)의 개수를 2개 이상으로 설정하면 된다.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
model = LinearRegression()
features = ['bathrooms','sqft_living']
target = ['price']
#훈련 데이터 설정
X_train = train[features]
y_train = train[target]
#테스트 데이터 설정
X_test = test[features]
y_test = test[target]
# 모델 fit 학습
model.fit(X_train, y_train)
y_pred = model.predict(X_train)
y_pred = model.predict(X_test)
# 예측하기
model.predict([[2000, 10]]) 과 같이 원하는 값을 2개를 넣어줘야 예측치가 나온다.
다중선형회귀모델의 시각화
1) 데이터의 분포 확인하기
# 3D 산포도 그리기
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import style
style.use('seaborn-talk')
fig = plt.figure()
# for 3d plot
ax = fig.gca(projection='3d')
ax.scatter(train['GrLivArea'], train['OverallQual'], train['SalePrice'])
ax.set_xlabel('GrLivArea', labelpad=12)
ax.set_ylabel('OverallQual', labelpad=10)
ax.set_zlabel('SalePrice', labelpad=20)
plt.suptitle('Housing Prices', fontsize=15)
plt.show()
# (참고) plotly를 사용해서 상대적으로 간단히 그래프를 그릴 수도 있습니다.
# px.scatter_3d(
# train,
# x='GrLivArea',
# y='OverallQual',
# z='SalePrice',
# title='House Prices'
# )
2) plotly 라이브러리를 사용하여 선형모델평면을 시각화
특성 2개로 이루어진 다중선형회귀모델은 선의 형태가 아닌 평면의 형태로 표현이 됩니다.
import numpy as np
import plotly.express as px
import plotly.graph_objs as go
import itertools
def surface_3d(df, f1, f2, target, length=20, **kwargs):
"""
2특성 1타겟 선형모델평면을 시각화 합니다.
df : 데이터프레임
f1 : 특성 1 열 이름
f2 : 특성 2 열 이름
target : 타겟 열 이름
length : 각 특성의 관측치 갯수
"""
plot = px.scatter_3d(df, x=f1, y=f2, z=target, opacity=0.5, **kwargs)
# 다중선형회귀방정식 학습
model = LinearRegression()
model.fit(df[[f1, f2]], df[target])
# 좌표축 설정
x_axis = np.linspace(df[f1].min(), df[f1].max(), length)
y_axis = np.linspace(df[f2].min(), df[f2].max(), length)
coords = list(itertools.product(x_axis, y_axis))
# 예측
pred = model.predict(coords)
z_axis = pred.reshape(length, length).T
# plot 예측평면
plot.add_trace(go.Surface(x=x_axis, y=y_axis, z=z_axis, colorscale='Viridis'))
return plot
다중선형회귀모델의 회귀계수
다중선형회귀모델의 회귀계수의 개수는 특성을 몇가지 사용하는가에 따라 달라집니다.
model.coef_를 사용하여 회귀계수를 파악하는 경우 b0,b1의 회귀계수가 순서대로 나열된다.
(이 나열된 회귀계수는 회귀분석을 학습할 때 설정한 feature의 순서대로 지정됨으로 참고해야한다.)
* 회귀계수의 크기를 통해 어떤 특성이 종속변수에 얼마나 영향을 더 끼치는 지를 확인이 가능하다.
회귀모델을 평가하는 평가지표들(evaluation metrics)

- MAE ( Mean Absolut Error )
- 절대값을 취하기 때문에 가장 직관적으로 알 수 있는 지표입니다.
- MSE 보다 특이치에 robust합니다. ( 특이치에 영향을 덜 받는다. )
- 절대값을 취하기 때문에 모델이 underperformance 인지 overperformance 인지 알 수 없습니다.
- underperformance: 모델이 실제보다 낮은 값으로 예측
- overperformance: 모델이 실제보다 높은 값으로 예측
- MSE( Mean Squared Error )

- 제곱을 하기 때문에 MAE와는 다르게 모델의 예측값과 실제값 차이의 면적의 합입니다.
- 이런 차이로, 특이값이 존재하면 수치가 많이 늘어납니다. ( 특이치에 민감하다 )
- SSE를 오차의 자유도로 나누어주는 이유
- 제곱 된 값은 항상 양수입니다
- 양수를 모두 더하게 되면, 데이터가 많을 수록 값은 커지게 됩니다.
- 그 의미는 SSE자체가 데이터가 많을 수록 단순히 커지는 의미이기 때문에, 정말 오차가 높은가? 에 대한 평가기준이 잘못 해석될 수가 있습니다.
- 이를 자유도로 나눔으로써 평균이 계산되고, 보정된 평균오차를 모형의 Error 수준으로 판단하게 됩니다.
- Root Mean Squared Error(RMSE)
- 오류 지표를 실제 값과 유사한 단위로 다시 변환하여 해석을 쉽게 합니다.
- RMSE는 "큰 오류값 차이에 대해서 크게 패널티를 주는" 이점이 있습니다.
- 즉 , MAE보다 특이치에 robust합니다. ( 특이치에 영향을 덜 받는다. )
- R제곱 (R-squared)
- R제곱의 크기가 1에 가까울 경우 해당 모델이 설득력이 있다고 판단합니다. ( 모형의 적합도를 평가하기 위해 사용 )
- 예측값(회귀선)과 평균 / 실제값과 평균의 차이를 비교하는 것 이다.
- R제곱의 문제점은 출력 변수와 아무런 관계가 없더라도 동일하게 유지되거나 더 많은 변수를 추가하면 증가한다
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 회귀방정식 평가지표
mse = mean_squared_error(y(타겟 열), y_pred(예측값))
mae = mean_absolute_error(y, y_pred)
rmse = mse ** 0.5
r2 = r2_score(y, y_pred)
과적합(Overfitting)과 과소적합(Underfitting)
일반화(generalization)
- 테스트데이터에서 만들어내는 오차를 일반화 오차라고 부릅니다.
- 훈련데이터에서와같이 테스트데이터에서도 좋은 성능을 내는 모델은 일반화가 잘 된 모델이라고 부릅니다.
- 모델이 너무 훈련데이터에 과하게 학습(과적합)을 하지 않도록 하는 많은 일반화 방법들이 있습니다.
- 과적합은 모델이 훈련데이터에만 특수한 성질을 과하게 학습해 일반화를 못해 결국 테스트데이터에서 오차가 커지는 현상을 말합니다
- 반대로 과소적합은 훈련데이터에 과적합도 못하고 일반화 성질도 학습하지 못해, 훈련/테스트 데이터 모두에서 오차가 크게 나오는 경우를 말합니다.
편향(Bias)과 분산(Variance)
다른 블로그에서 본 것과 같이 제가 이해한 바를 좀 쉽게 풀어내자면,
편향(Bias)는 실제값과 예측값(회귀분석값)의 차이라고 보면 이해가 쏙.
분산(Variance)는 회귀분석선의 변동선, 일정한 패턴을 가지고 있는가라고 보면 이해가 쏙.
즉,
- 분산이 높은경우는, 모델이 학습 데이터의 노이즈에 민감하게 적합하여 테스트데이터에서 일반화를 잘 못하는 경우 즉 과적합 상태입니다.
- 편향이 높은경우는, 모델이 학습 데이터에서, 특성과 타겟 변수의 관계를 잘 파악하지 못해 과소적합 상태입니다.
좀더 풀어서 설명하자면
- Low Bais라는 것은 실제값과 예측값의 차이를 없애기 위해 실제값을 모두 지나도록 회귀선을 변화시키는 것이고, 그렇게 회귀선을 변형시켜 학습시키게 되면 일정한 패턴이 아닌 형태를 띄기 때문에 High Variance가 됩니다.
- Low Variance라는 것은 회귀선이 일정한 패턴을 지니게 하는 것임으로 직선의 형태에서 많이 변화하지 않고, 그러한 형태는 실제값과 예측값의 차이가 존재하여 High Bais 가 됩니다.
이와중에 편향과 분산이 모두 낮은 경우가 있는 데 그런 경우는 충분히 학습이 되지 않은 것으로 판단할 수 있습니다.
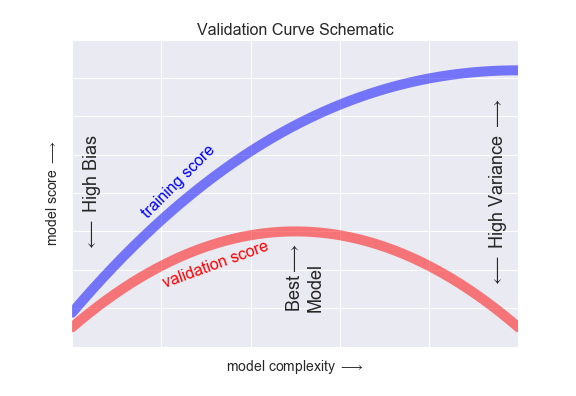
위의 그림을 통해서 모델 복잡도가 올라감에 따라 훈련 스코어는 계속해서 높아지지만 검증 스코어는 다시 내려가는 것을 볼 수 있습니다.
그리하여 최적의 모델은 훈련 스코어도 높으면서 검증 데이터가 최고점을 보여주는 상태입니다.
'AI 일별 공부 정리' 카테고리의 다른 글
| 회귀 분석 - 4 (Logistic Regression) (0) | 2021.08.13 |
|---|---|
| 회귀 분석 - 3 (Ridge Regression) (0) | 2021.08.12 |
| 회귀 분석 - 1 (단순선형회귀모델) (0) | 2021.08.09 |
| 데이터를 적절하게 시각화 해보자 -2 ( feat. python) - 순위, 계층구조 (0) | 2021.08.06 |
| 데이터를 적절하게 시각화 해보자 -1 ( feat. python) - 분포, 상관관계 (0) | 2021.08.05 |



