
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 서비스기획
- 유데미큐레이션
- 스타터스
- 유데미코리아
- NLP
- 특성중요도
- NLU
- 취업부트캠프
- 그래프
- MatchSum
- 부트캠프후기
- 취업부트캠프 5기
- 추천시스템
- 딥러닝
- 유데미부트캠프
- AARRR
- 데이터도서
- 토스
- 알고리즘
- 임베딩
- pytorch
- 스타터스부트캠프
- SLASH22
- 그로스해킹
- AWS builders
- SQL
- 서비스기획부트캠프
- BERT
- sql정리
- 사이드프로젝트
- Today
- Total
다시 이음
알고리즘(5) - 해시(Hash) 본문
안녕하세요.
오늘 부터는 알고리즘 자료구조의 중급 과정이라고 할 수 있는 부분을 살펴보려고 합니다.
첫 주자는 해시(Hash)인데요.
해시라고 하면 해시태그를 먼저 생각하실 수 도 있는데 이 해시태그(#)와는 상관이 없습니다.
대신 블록체인에서 해시함수는 중요한 원리로 작용한다고 합니다.
어떤 부분에서 활용되는지는 본문에서 해시에 대해서 공부를 하고 다시 찾아보면 이해가 되실 겁니다.
해시(Hash)
1. 해시 테이블(Hash Table)

해시 테이블은 키(key)와 값(value)이 쌍을 이뤄 매핑할 수 있는 추상 자료 구조 입니다.
이 키와 값을 매핑시키는 과정을 해싱(Hashing) 이라고 합니다.
키가 매핑이 되기 위하여 해시함수를 거쳐 해시값(정수값)에 매핑이 되는 과정을 가지고 있습니다.
해시 테이블의 장점
- 빠른 탐색 , 삽입, 삭제 속도를 가지고 있습니다.
- 데이터 양에 따라 속도 차이가 크지 않습니다.
- 이전에 배운 연결리스트 같은 선형탐색과 달리 O(1)의 시간복잡도를 가집니다.
- 그러나 정렬 순서가 최악의 경우에는 시간복잡도 O(N)이 됩니다.
❄️ 이진탐색 = O(logn) , 선형탐색 = O(N) 시간복잡도를 가집니다.
2. 해시함수(Hash Function)
해시 함수란, 앞서 설명한 것과 같이 키를 값에 매핑하기 위해 거치는 과정입니다.
해시함수의 특징에 대해서 살펴볼게요.
1) 일관성
같은 입력값(key)을 넣어준다면 같은 출력값(value)를 출력해줘야 합니다.
2) 개별성
일관성과 같은 맥락으로 다른 입력값이면 모두 다른 출력값을 출력하는 것이 좋은 해시 함수입니다.
하지만, 이와 같은 함수를 만드는 것은 매우 힘듭니다.
그렇기 때문에 입력값에 대해 다른 출력값을 도출하는 해시충돌을 최소화 하는 해시함수가 좋은 해시함수입니다.
3) 유효성
입력값의 종류가 10가지가 있는데 출력값의 종류(배열)가 5가지 밖에 안된다면 해시충돌이 불가피합니다.
인덱스가 유효하도록 입력값의 종류보다 더 많은 출력값 인덱스를 확보하는 것이 해시충돌을 막을 수 있는 하나의 방법일 것입니다.
3. 해시충돌 ( Collision )
위에서 언급한 것과 같이
1) 하나의 출력값에 하나 이상의 입력값이 매핑된 경우
2) 입력값의 종류보다 출력값의 종류가 적어서 매핑되는 배열이 유효하지 않은 경우
위의 경우들을 모두 해시충돌이라고 합니다.
위의 해시충돌을 보면서 해시충돌을 방지하고 싶다는 생각이 들진 않으셨나요?
해시충돌 방지법
1) 체이닝 (Chaining)
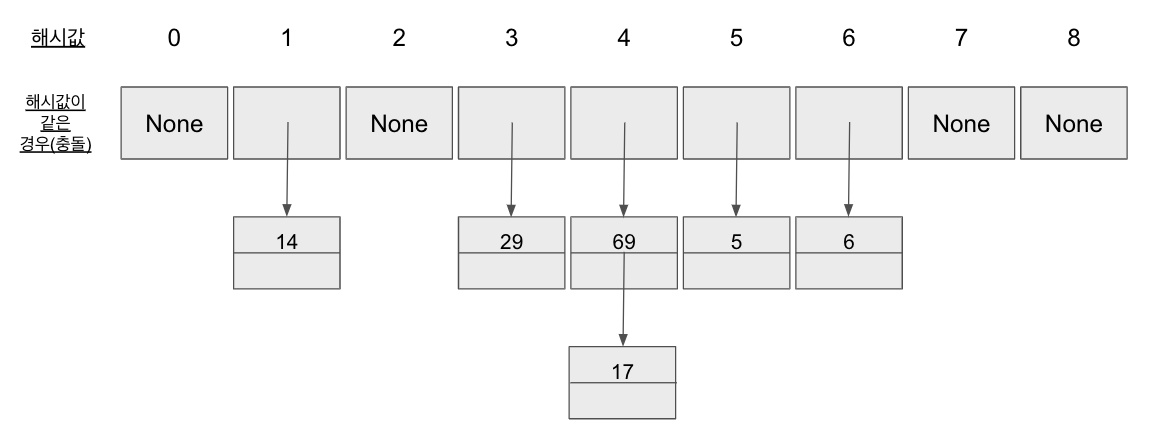
위에서 한 가지 이상의 입력값이 해시함수를 거쳐 같은 출력값을 가지는 경우에도 해시충돌이라고 했습니다.
같은 인덱스의 값을 가지게 된 경우 다른 인덱스를 매핑하는 방법 외에는 해결 방법이 없는 것일까요?
답은 아닙니다.
위의 체이닝 방법을 이용하면 같은 해시값을 가지더라도 해시충돌을 방지할 수 있습니다.
그 방법은 같은 해시값을 가진 값을 연결리스트로 추가 입력하는 방법입니다.
예를 들어서 어떻게 활용되는지 알아볼게요.
우리는 10개의 배열을 토대로 매핑을 시켜보도록 하겠습니다.
[] 리스트가 10개 이어 붙여진 형태입니다.
우리는 key값을 10으로 나누어 나머지 값에 따라 해시값을 매핑하는 나누기 방법(divide method)를 사용하겠습니다.
[(10:A),(3:B),(5:C),(30:D),(8:E)]의 key:value 형태를 띄고 있는 입력값을 매핑하겠습니다.
*체이닝을 사용하지 않은 경우
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| D | None | B | C | E |
❄️ 0의 해쉬값에 가장먼저 배정되었던 A 값이 나중에 매핑된 (30:D)에 대치되어 D의 값만 가지게 됩니다.
*체이닝을 사용한 경우
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| A, D | None | B | C | E |
❄️ 0의 해쉬값에 연결리스트로 추가되어 2가지의 값을 가집니다.
2) 오픈어드레싱(Open addressing)

위의 오픈 어드레싱 방법은 해시충돌을 방지하는 방법중에 하나로 하나의 해시 인덱스에 여러가지의 값을 넣는 것(체이닝)이 아닌 다른 인덱스에 비어있는 인덱스를 찾아 매핑하는 방법입니다.
이러한 매핑 방법은 충돌이 일어날 시에 발동하게 되며 배열의 길이가 정해져 있기 때문에 데이터가 뭉치는 현상(클러스터링)이 자주 일어납니다.
또한 단점으로 모든 원소가 반드시 자신의 해시값과 일치하는 주소에 저장된다는 보장은 없습니다.
이렇게 데이터가 뭉치는 현상은 데이터가 충분히 흩어져 있는 방식보다 효율이 떨어집니다.
파이썬에서 리스트는 오픈 어드레싱 방법을 사용하고 있습니다.
로드팩터(Load Factor)

로드팩터란?
해시 테이블의 데이터 개수 / 해시 버킷 수 입니다.
즉, 로드 팩터는 해시 테이블이 얼마나 가득 찼는지 측정하는 단위 입니다.
이 로드 팩터의 값이 작을 수록, 해시 성능이 높아집니다.
로드팩터에 관하여 깊게 들어가지 않기 위해서 간단하게 체이닝을 사용할 경우 로드 펙터의 값이 1의 값 이하라고 보고,
오픈 어드레싱의 경우에도 로드 팩터의 값이 1을 넘을 수 없습니다.
(체이닝의 경우에는 1이 넘는 경우가 있다고 합니다만 그러한 경우는 대학교 논문 수준에서 예외적으로 거론되는 부분이기 때문에 위처럼 이해하는 게 좋습니다.)
좀더 설명을 하자면
체이닝의 경우, 데이터가 많이 늘어난다고 하더라도 슬롯 전체를 채우지 않고 연결리스트를 통해 비어있는 슬롯을 유지할 수 있기 때문에 로드 팩터는 1이하입니다.
오폰 어드레싱의 경우에도 슬롯이 부족하게되면 추가적으로 슬롯을 만들어서 저장하기때문에 로드 팩터가 1이 되는 경우는 없습니다.
(여기서 오픈 어드레싱은 용량의 75-80%이상(컴퓨터 언어에 따른 차이)이 차는 경우 급격하게 성능이 줄어들기 때문에 추가적으로 용량을 확보하는 조치를 취해서 성능을 유지하는 방법을 사용합니다.)
해시의 활용
처음 글을 시작할 때 블록체인에 해시 원리가 사용된다고 했습니다.
그 원리의 기초가 되는 것이 역상저항성 입니다.
역상저항성이란 예를 들어 1+2 을 연산하면 3이 되는 것은 쉽지만, 그 반대로 3만 주어졌을 때 그 전의 연산이 1+2인지 2+1인지 0.1234 + 2.8766 인지 추론하는 방법은 거의 불가능에 가깝다는 원리입니다.
이러한 원리 이외에도 암호화 해시라는 키워드로 검색을 해보시면 블록체인이 왜 안전성이 그렇게 높다고 하는 것인지 고유한 NFT같은 값을 가지게 할 수 있는 것인지를 알아볼 수 있는 기회가 될 것 같습니다.
그러한 내용은 이 블로그에 들어가셔서 한번 읽어보시면 참고가 될 것 같습니다.
'AI 일별 공부 정리' 카테고리의 다른 글
| 알고리즘(7) - BFS,DFS (0) | 2021.12.05 |
|---|---|
| 알고리즘(6) - 그래프 자료구조 (0) | 2021.12.02 |
| 알고리즘(4) - 퀵정렬, 병합정렬 (Quick sort, Merge sort) (0) | 2021.11.30 |
| 알고리즘(3) - 탐색, 정렬 (0) | 2021.11.27 |
| 알고리즘(2) - 비선형 자료구조, 재귀(Recursion) (0) | 2021.11.25 |


