
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 유데미코리아
- 취업부트캠프 5기
- SLASH22
- AARRR
- sql정리
- 딥러닝
- 임베딩
- 그로스해킹
- 스타터스부트캠프
- NLU
- MatchSum
- 서비스기획부트캠프
- 부트캠프후기
- 취업부트캠프
- 데이터도서
- 그래프
- pytorch
- 특성중요도
- 유데미부트캠프
- BERT
- 사이드프로젝트
- 서비스기획
- 유데미큐레이션
- 스타터스
- AWS builders
- 토스
- 추천시스템
- SQL
- 알고리즘
- NLP
- Today
- Total
다시 이음
알고리즘(6) - 그래프 자료구조 본문
안녕하세요.
오늘은 자료구조 중급의 두번째 그래프(Graph)에 대해서 알아보겠습니다.
이 그래프 자료구조는 트리 자료구조와 많이 비교가 이루어지는 자료구조 입니다.
그만큼 비슷한 점도 있고 차이점도 있는 구조입니다.
그래프(Graph)
위에서 언급한 것과 같이 트리 구조와 어떤 부분이 비슷하고 어떤 부분에서 차이를 보일까요?
그래프란?
그래프는 노드(=정점,vertex) 와 엣지(=링크,간선)로 구성된 구조입니다.
이러한 구성에 대해서는 어느 정도 연관성을 가지고 있는 구조이지만,
트리 구조는 노드 간에 계층 구조를 나타나고 그래프는 노드간에 관계를 나타낸다는 차이점이 있습니다.
그래프에서 노드간에 관계란 실제의 object간의 관계를 보여주기 때문에 보통 SNS, 도로 상의 차량 검색, 운송시스템 등 우리 주변에서 많이 쓰이는 자료구조중에 하나입니다.
그래프의 구분
1) 방향성
: 방향성을 가지고 있는가 에 따른 구분으로 방향성을 가질 경우 Directed, 방향성이 없이 상호교환되는 경우 Undirected(무방향) 로 구분합니다.
- Directed
- 단방향(One-way)
- 양방향(Bidirectional)
- Undirected
2) 순환성
: 트리구조와 차이점 중에 하나인 순환(루프)을 가지고 있는지에 대한 구분입니다.
- Cyclic(순환) : 어떠한 노드에 다시 돌아올 수 있는 루프를 가지고 있는 경우 ( Undirected는 상호교환이 가능함으로 순환 그래프입니다.)
- Acyclic(비순환) : 루프가 없는 경우
3) 가중치
: 구성 요소중 하나인 Egde(간선)은 가중치를 가질 수 있습니다. 경로의 총 가중치가 높을수록 경로이동시간(비용)이 커집니다.
- Unweighted
- 가중 그래프(weighted)
4) DAGs
: Directed Acyclic Graphs 순환이 없는 단방향 그래프입니다.
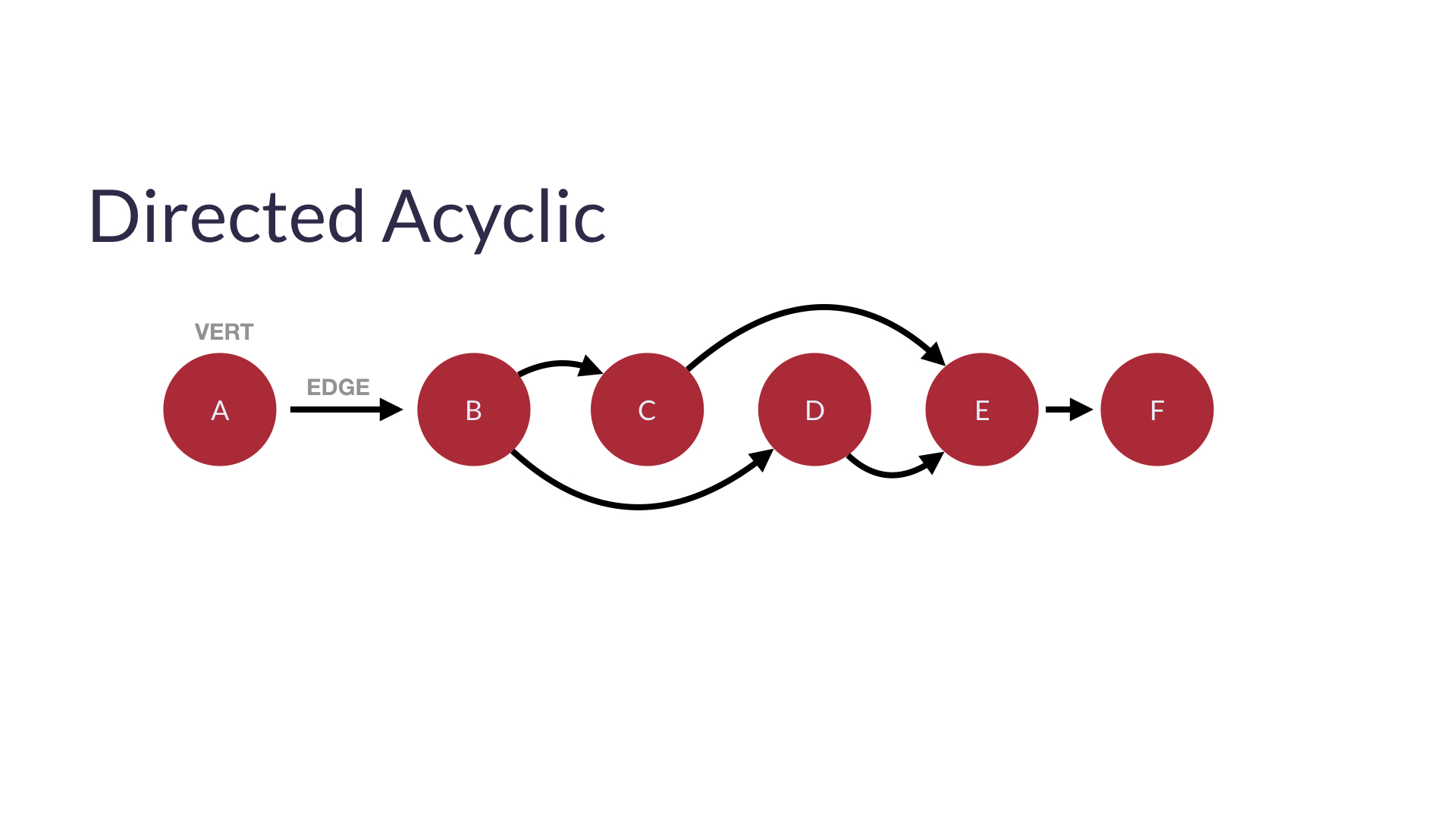
그래프의 구현 방법
1) 인접리스트(adjacency lists)
그래프의 연결 관계를 vector의 배열로 표현하는 방법입니다.
인접리스트의 단점으로는 특정 노드간의 연결관계를 확인하기 위해서는 반복문이 활용해야 합니다.
graph = {
"A": {"B"}, # 여기서 {"B"}가 set의 형태이다.
"B": {"C", "D"}, # {"B" : {}}의 형태는 딕셔너리
"C": {"E"}, # 즉, 딕셔너리 안에 set이 있는 것이다.
"D": {"F", "G"}
}
2) 인접행렬(adjacency matrices)
인접 행렬은 그래프의 연결 관계를 2차원 배열로 표현하는 방법입니다.
아래의 예시와 같이 숫자를 통해 가중치의 값을 쉽게 구현할 수 있습니다.
단점이라고 하면 아래와 같이 어떤 노드의 엣지에 가중치가 어떻게 적용되는 지 한눈에 파악하기가 어렵습니다.
그렇기 때문에 특정노드에 방문한 노드들을 알기 위해서는 모든 노드를 확인해야 합니다.
Graph:[[0,1,0,0,0,0,0],
[0,0,1,1,0,0,0],
[0,0,0,0,1,0,0],
[0,0,0,0,0,1,1],
[0,0,1,0,0,0,0]]
그래프 G(V,E)를 통해 예시를 들어 인접리스트와 인접행렬의 차이점을 비교해보도록 하겠습니다.
V= 노드의 개수 N개, E = 간선의 개수 M개
노드 1 : U, 노드2 : V
| 인접행렬 | 인접리스트 | |
| Memory | O(N^2) | O(N+M)(더 좋음) |
| U와 V 간에 엣지(간선)가 존재하는가? | O(1)(더 좋음) : U,V행렬을 찾아 바로 값을 찾을 수 있습니다. |
O(N) : 간선 확인을 위해서는 리스트 내부 값을 하나하나 탐색해야 합니다. |
| U에 인접한 모든 노드 v에 대해서 특정 액션을 취해라(for문) | O(N) | O(인접한 노드 수) |
| 삽입 | O(1) | O(1) (연결리스트일땐 왼쪽에 삽입-삽입을 위해 마지막 인덱스 탐색을 해야해서 수고를 덜기 위해 왼쪽에 삽입, 리스트일땐 오른쪽에 삽입) |
| 삭제 | O(1) | O(N) |
순회 (Traversal)
순회의 목적은 모든 노드 또는 특정 노드를 방문하는 방법을 찾는 것(탐색)입니다.
그래프와 트리의 순회구분
1) 그래프의 순회
: DFS(깊이우선탐색), BFS(너비우선탐색) 탐색 알고리즘 방법이 있습니다.
그래프는 루트, 부모, 자식노드 개념이 없지만 전위, 중위, 후위순회의 순회개념을 활용하여 DFS, BFS를 구현할 수 있습니다.
2) 트리의 순회
: 전위순회, 중위순회, 후위순회 방법이 있습니다.



- 전위순회(preorder traverse) : 루트를 먼저 방문 -- Middle -> Left -> Right
- 중위순회(inorder traverse) : 왼쪽 서브트리를 방문 후 루트방문 -- L->M->R
- 후위순회(postorder traverse) : 순서대로 서브트리(왼쪽->오른쪽)를 모두 방문 후 루트를 방문. -- L->R->M
❄️ 트리 순회 예시
A
/ \
B C
/ \ / \
D E F G
/ \
H I
: 서브트리로 나누어 생각하면 좀더 쉽게 파악할 수 있습니다.
전위순회 - MLR : [A] [BDHIE] [CFG] 순서
중위순회 - LMR : [HDI] [BE] [A] [FCG] 순서
후위순회 - LRM : [HID] [EB] [FGC] [A] 순서
F
/ \
B G
/ \ \
A D I
/ \ /
C E H
전위순회 [F] [BAD] [CE] [GIH]
중위순회 [AB] [CDE] [F] [GHI]
후위순회 [ACEDB] [HIG] [F]
'AI 일별 공부 정리' 카테고리의 다른 글
| 알고리즘(8) - 동적 프로그래밍(Dynamic Programing), 그리디(Greedy) (0) | 2021.12.06 |
|---|---|
| 알고리즘(7) - BFS,DFS (0) | 2021.12.05 |
| 알고리즘(5) - 해시(Hash) (0) | 2021.12.01 |
| 알고리즘(4) - 퀵정렬, 병합정렬 (Quick sort, Merge sort) (0) | 2021.11.30 |
| 알고리즘(3) - 탐색, 정렬 (0) | 2021.11.27 |



