
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 부트캠프후기
- 데이터도서
- NLU
- 취업부트캠프 5기
- 토스
- 스타터스
- 서비스기획부트캠프
- 유데미부트캠프
- AWS builders
- 사이드프로젝트
- AARRR
- MatchSum
- NLP
- 임베딩
- 서비스기획
- sql정리
- pytorch
- 추천시스템
- BERT
- 취업부트캠프
- 특성중요도
- 그래프
- 스타터스부트캠프
- 딥러닝
- SQL
- SLASH22
- 유데미코리아
- 유데미큐레이션
- 그로스해킹
- 알고리즘
- Today
- Total
다시 이음
알고리즘(7) - BFS,DFS 본문
안녕하세요.
오늘은 직전에 같이 배웠던 순회에서 자료구조인 그래프의 순회에 대해서 배워보려고 합니다.
그래프의 순회는 트리 순회와 비슷하게 진행 방향에 따른 구분입니다.
BFS(Breadth-first-search) - 너비 우선 탐색
BFS 란?
그래프의 순회방법 중 인접한 노드부터 탐색해나가는 탐색 방법입니다.
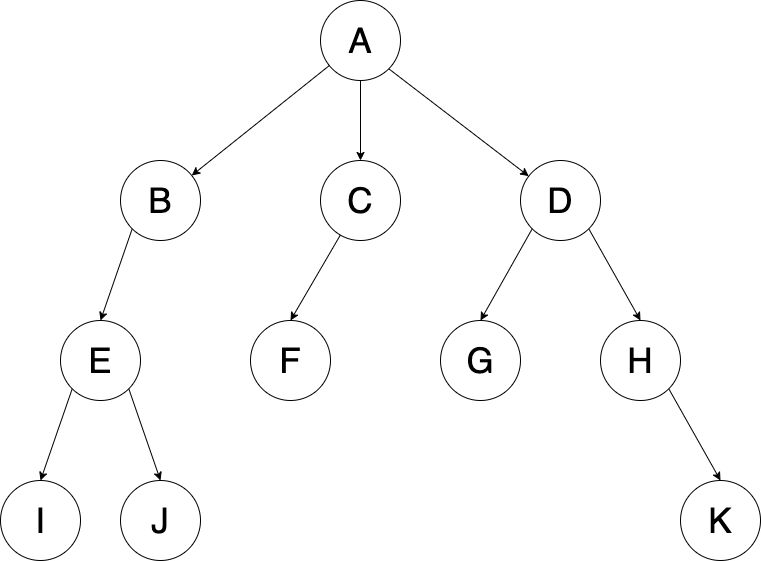
위의 예시를 통해서 어떻게 BFS가 진행되는지 같이 살펴보도록 하겠습니다.
BFS는 위에서 정의한 것과 같이 인접한 노드부터 탐색합니다.
좀더 쉽게 말하면 예전에 트리구조 용어에서 LEVEL이라는 단어를 들어보셨을 겁니다.
그 LEVEL에 따라 탐색을 진행한다고 생각하시면 됩니다.
시작 노드를 'A'로 지정한 경우에는 B-C-D가 인접한 노드로 먼저 탐색을 시작하고 그다음 레벨인 E-F-G-H 순으로 탐색을 이어갑니다.
그래서 전체적으로는 A → B → C → D → E → F → G → H → I → J → K 순서대로 탐색을 진행하게 됩니다.
위에서 든 예시는 이해하기 쉽도록 트리 구조형태의 그래프를 예시로 들었습니다.
하지만 그래프의 경우 트리 구조와 같이 단방향뿐만아니라 양방향 일 수도 있고, 계속해서 순환되는 구조를 가지기도 한다고 이전 시간에 배웠습니다.
그런 경우 BFS는 어떻게 탐색을 진행할까요?
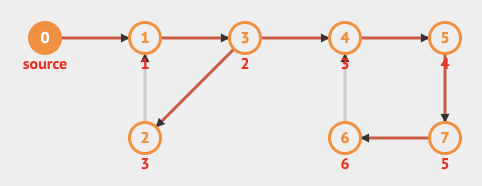
위의 예시를 보면 [1,3,2], [4,5,6,7]은 순환 구조를 띄고 있습니다.
이러한 경우 BFS는 0→ 1→ 3→ 2→ 4→ 5→ 7→ 6 순서로 탐색을 진행합니다.
BFS의 특징
- 선입선출의 개념을 가지는 큐(queue)를 활용합니다.
- 노드가 적은 경우 최단경로를 탐색할 때 유용합니다.
- 큐를 활용하므로 노드가 많아지는 경우 메모리 저장공간이 증가하는 단점이 있습니다.
BFS 코드 구현
큐를 활용한 코드 구현이기 때문에 선입선출 개념을 한번더 생각하면서 코드를 보면 좋습니다.
def bfs_queue(start_node):
bfs_list = [start_node] # 최종적으로 결과를 저장할 리스트
queue = [start_node] #다음 레벨 노드로 넘어갈 순서 리스트
while queue:
node = queue.pop(0) #리스트에 저장한대로 왼쪽부터 차례대로 pop합니다.
for i in bfs_graph[node]:
if i in bfs_list: #탐색한 노드를 다시 탐색하지 않기위한 조건문
continue
else:
bfs_list.append(i)
queue.append(i)#선입선출 특징의 큐를 사용하기때문에 append로 가능합니다.
return bfs_list
DFS(Depth-first-search) - 깊이 우선 탐색
DFS 란?
그래프 자료구즈를 깊게 있는 노드부터 순서대로 뻗어가는 탐색 방법입니다.
DFS는 BFS와 다르게 인접한 노드보다는 깊게 있는 노드부터 탐색합니다.
A가 시작노드라면, B-E-I 순으로 왼쪽에서 가장 깊은 순서부터 탐색하는 구조를 띕니다.
전체적으로 A → B → E → I → J → C → F → D → G → H → K 순서대로 탐색을 하게됩니다.
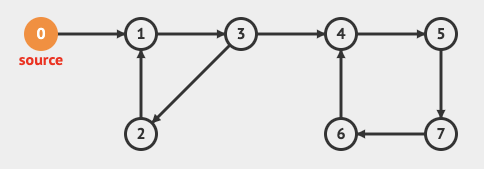
이런 순환 그래프 구조에서는 DFS는 어떻게 탐색을 진행할까요?
0→ 1→ 3→ 2→ 4→ 5→ 7→ 6 과 같이 왼쪽에서 깊은 2까지 탐색한 후에 갈림길인 곳에서 다시 탐색을 시작하여 6에서 탐색을 마무리하게 됩니다.
DFS의 특징
- backtracking 방법을 사용합니다. ( 노드가 있을만한 곳을 되돌아가서 모두 살펴본다는 개념 )
- 후입선출의 개념을 가지는 스택(stack)를 활용합니다.
- 모든 노드를 방문하는 경우 사용됩니다.
- 단점으로는 최단 경로를 찾지 못하고, 시간이 오래 걸릴 수 있습니다.
DFS 코드 구현
#1. 스택을 사용한 코드 구현
def dfs_stack(start_node):
dfs_list = [] #BFS와 다르게 startnode를 안넣는 이유는?
stack_list = [start_node] #탐색할 노드 리스트
while stack_list:
node = stack_list.pop() #후입선출이기때문에 뒤에서 pop
dfs_list.append(node) #탐색하면 DFS리스트에 저장
for i in reversed(dfs_graph[node]): #탐색할 노드 리스트(stack_list)에 거꾸로 입력을 해야 후입선출이 가능합니다.
if i in dfs_list:
continue
else:
stack_list.append(i)
return dfs_list
#2. 재귀를 활용한 코드 구현
def dfs_recur(node, dfs_list=[]):
dfs_list.append(node
for i in dfs_graph[node]: # 노드의 인접한 노드를 기준으로 반복한다.
if i in dfs_list:
break
else:
dfs_recur(i)
return dfs_list❄️ 위의 코드가 왜 이렇게 작성되었는지 알아보겠습니다.
1) 스택 구현에서 왜 reversed()를 사용하여 append를 하였을까요?
- 우리는 위의 코드를 실행하기 위해서는 그래프를 인접리스트(adjacency lists)로 표현해야합니다.
dfs_graph = { # 그래프를 인접리스트로 표현
"A": ['B','C','D'],
"B": ['E'],
"C": ['F'],
"D": ['G','H'],
"E": ['I','J'],
"F": [],
"G": [],
"H": ['K'],
"I": [],
"J": [],
"K": []
}반복문 진행에 따라 dfs_list와 stack_list가 어떻게 변화하는지를 보면서 이해를 하기 쉽게 해드릴게요.
1)
before
dfs_list : []
stack_list : [A]
after
dfs_list : [A]
stack_list : [A, D, C, B]
2)
before
dfs_list : [A]
stack_list : [A, D, C, B]
after
dfs_list : [A,B]
stack_list : [A, D, C, B, E]
3)
before
dfs_list : [A,B]
stack_list : [A, D, C, B, E]
after
dfs_list : [A,B,E]
stack_list : [A, D, C, B, E, J, I]
4)
before
dfs_list : [A,B,E]
stack_list : [A, D, C, B, E, J, I]
after
dfs_list : [A,B,E,I]
stack_list : [A, D, C, B, E, J, I]
5)
before
dfs_list : [A,B,E,I]
stack_list : [A, D, C, B, E, J, I]
after
dfs_list : [A,B,E,I,J]
stack_list : [A, D, C, B, E, J, I]
6)
before
dfs_list : [A,B,E,I,J]
stack_list : [A, D, C, B, E, J, I]
after
dfs_list : [A,B,E,I,J,C]
stack_list : [A, D, C, B, E, J,I, F]
7)
before
dfs_list : [A,B,E,I,J,C]
stack_list : [A, D, C, B, E, J,I, F]
after
dfs_list : [A,B,E,I,J,C,D]
stack_list : [A, D, C, B, E, J,I, F, H, G]
8)
before
dfs_list : [A,B,E,I,J,C,D]
stack_list : [A, D, C, B, E, J,I, F, H, G]
after
dfs_list : [A,B,E,I,J,C,D, G]
stack_list : [A, D, C, B, E, J,I, F, H, G]
9)
before
dfs_list : [A,B,E,I,J,C,D,G]
stack_list : [A, D, C, B, E, J,I, F, H, G]
after
dfs_list : [A,B,E,I,J,C,D,G,H]
stack_list : [A, D, C, B, E, J,I, F, H, G, K]
10)
before
dfs_list : [A,B,E,I,J,C,D,G,H]
stack_list : [A, D, C, B, E, J,I, F, H, G, K]
after
dfs_list : [A,B,E,I,J,C,D,G,H,K]
stack_list : [A, D, C, B, E, J,I, F, H, G, K]
2) 재귀가 스택보다 너무 간단하게 구현된거 같아요.
- 재귀가 반복문과 스택이 결합된 방식인걸 기억하시나요? 위의 스택의 내용을 함축하여 표현하기 때문에 더 짧게 표현이 됩니다.
정리
| BFS(너비 우선 탐색) | DFS( 깊이 우선 탐색 ) |
| 큐 (FIFO, 선입선출) | 스택,재귀 (LIFO, 후입선출) |
| 현재 정점에 연결된 가까운 노드부터 탐색 | 왼쪽으로 가장 깊은 노드를 탐색하고 분기점이 되는 노드부터 다시 탐색 |
| 찾는 노드가 인접할수록 좋음 | 찾는 노드가 깊을 수록 빠르게 탐색 |
| 최단경로 찾기에 적합 (맨처음 도착한 노드가 최단경로) | 모든 노드를 찾기에 적합( 탐색을 위해선 모든 노드를 탐방해야함) |
| 사용하는 메모리 많음 | 사용하는 메모리 적음 |
❄️ BFS와 DFS 메모리 차이 이유?
BFS는 같은 레벨에 있는 노드를 모두 메모리에 저장하고 다음 레벨로 나아가면 리셋합니다. 그에 비해 DFS는 탐색하고 있는 라인에 대한 노드만 메모리에 저장합니다.
'AI 일별 공부 정리' 카테고리의 다른 글
| 시계열 데이터 예측에 대하여(Forecasting: Principles and Practice)-(1) (0) | 2021.12.30 |
|---|---|
| 알고리즘(8) - 동적 프로그래밍(Dynamic Programing), 그리디(Greedy) (0) | 2021.12.06 |
| 알고리즘(6) - 그래프 자료구조 (0) | 2021.12.02 |
| 알고리즘(5) - 해시(Hash) (0) | 2021.12.01 |
| 알고리즘(4) - 퀵정렬, 병합정렬 (Quick sort, Merge sort) (0) | 2021.11.30 |


